Pandasのデータフレームで列を追加することはよくあると思いますが、PySparkでも同様にSpark DataFrameに列を追加したいことがあると思います。
======================================================
これからデータサイエンスを学んでいきたいという方向けに「Pythonによるデータサイエンス」動画を提供しています。
基礎編・応用編それぞれ35時間以上の動画となっており、今なら約60%OFFですので、ぜひチェックしてみてください!
Spark DataFrameに列を追加
Pandasで列を追加したかったら例えば以下のようにすればできますよね。
|
1 |
df["add"] = 1 |
これは"add"列を追加して値は全て1になっている例ですが、PySparkではwithColumnsというメソッドを使って行います。
例えば、このようなSpark DataFrameがあるとします。
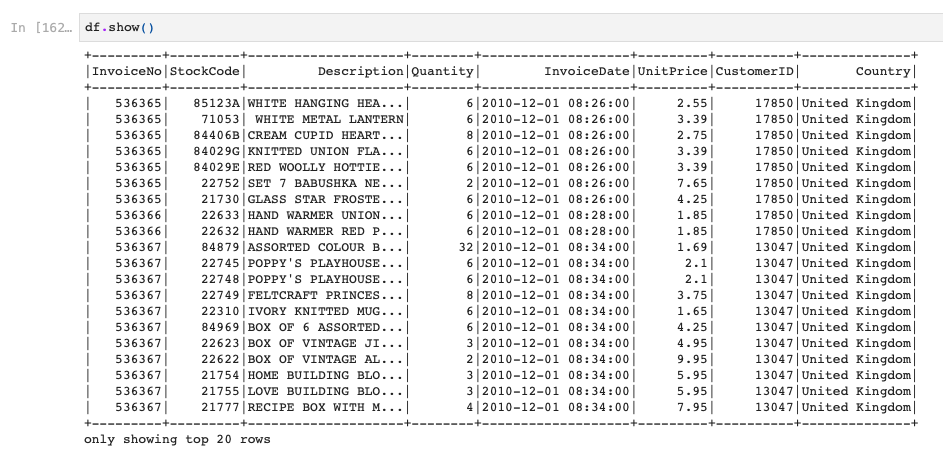
こちらはOnline Retailのデータセットを読み込んだものです。
この時に、UnitPrice列とQuantity列を使って、合計額を意味する"amount"列を作ってみたいと思います。
やり方は以下の通りです。
|
1 2 |
#withColumn df.withColumn("amount", df['UnitPrice']*df['Quantity']).show() |
withColumnメソッドの第一引数には新しく作る列名を入れ、第二引数に新しい列の値を表す計算式などを入れます。
今回はUnitPrice列×Quantity列でamount列としますので、上記のように掛け算をしています。
結果はこちらです。
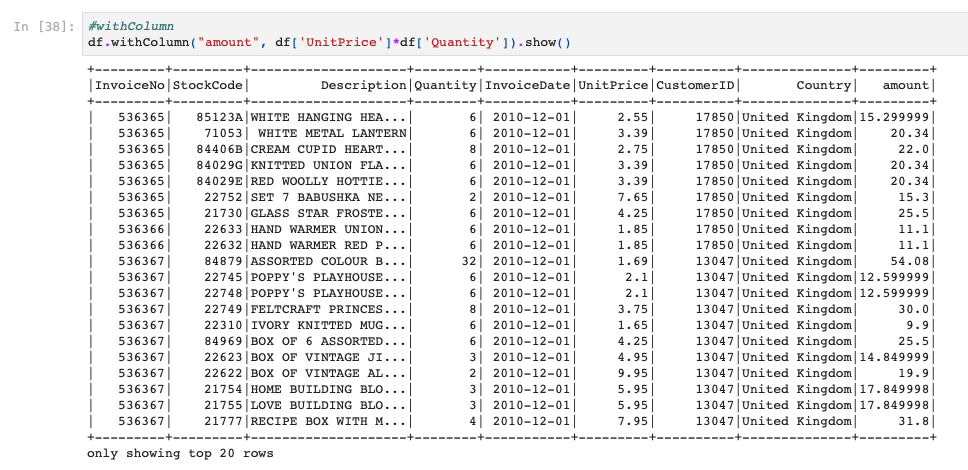
ちゃんと新しく列を作ることができていますね!
固定値とかを入れたい場合は、以下のようにlit(0)などとすればOKです。
|
1 |
df.withColumn("flag", lit(0)).show() |
Spark DataFrameの列名を変更
次に列名の変更方法も紹介したいと思います。
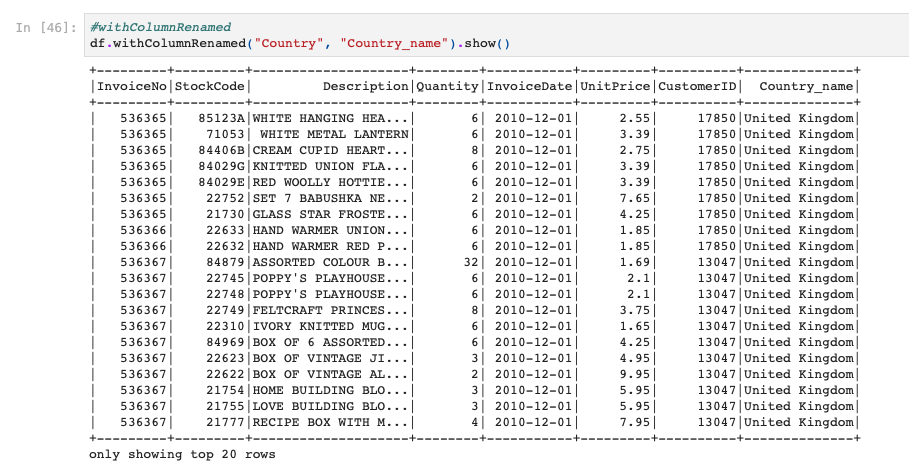
列名の変更はwithColumnRenamedメソッドを使います。
こちらの第一引数に変更したい列名を入れ、第二引数に変更後の列名を入力します。
例として、"Country"列を"Country_name"列にしてみます。
|
1 2 |
#withColumnRenamed df.withColumnRenamed("Country", "Country_name").show() |
ちゃんと列名が変わっていますね!
PySparkでSpark DataFrameではこのようにwithColumnやwithColumnRenamedメソッドを使って、新しく列を作ったり、列名を変更したりします。
PySparkの勉強法
もしPySparkをちゃんと学びたい方はUdemyのコースがおすすめです。日本語の書籍は古いやつしかないからです。。。
【Udemy】PySparkによる大規模データ処理手法と機械学習
英語でもよい方は英語のこのあたりがわかりやすいです。