
今回はPySparkでのgroupByによる集計処理を書いておきます。
集計は本当によくやる処理ですし、PySparkでももれなくSpark DataFrameの処理に使いますから、しっかりやっていきましょう!
ちなみに"groupby"は"groupBy"のエイリアスなんだそうですので、こちらでも使えます。
https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrame.groupBy.html
こんにちわ、サトシです。33歳です。 今回は、データサイエンティストの3年間に3社で働いた僕が、データサイエンティストとしての転職活動についてまとめて書きたいと思います。 これまでSE→博士研究員→ポ ... こんにちわ、サトシです。 今回は、企業でデータサイエンティストとして働いていた僕が、フリーランスとしてどのような手順で独立していったかについて書いていきたいと思います。 僕はSIer SE→博士過程→ ...

データサイエンティストとして3年間で3社経験した僕の転職体験談まとめ

データサイエンティスト経験3年の僕がフリーランスとして独立するまでの体験談
集計とカウント
まずはgroupbyをするときの典型例である集計してカウントをする処理をやってみます。
データはこちらのOnline Retailデータです。
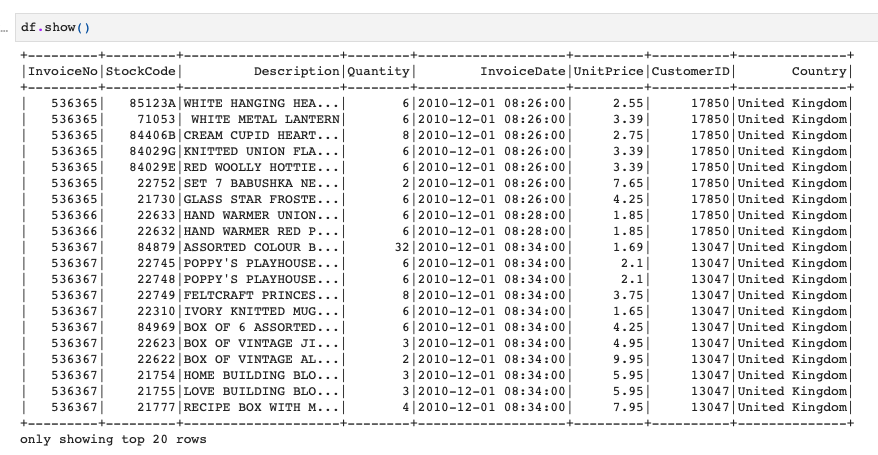
Desctiption列でgroupbyして、それぞれのDescriptionのカウントをしてみます。
|
1 |
df.groupby(df['Description']).count().show() |
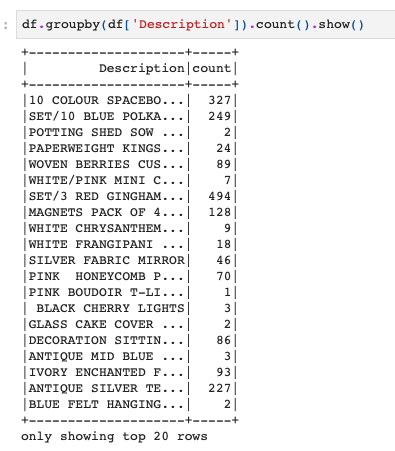
あまり違和感はないのではないでしょうか。
Pandasとかでやったことがあれば同じような感じですね。
次は、上のやつにちょっと追加でカウント数でソートする処理も加えてみます。
|
1 2 |
from pyspark.sql.functions import desc df.groupby(df['Description']).count().sort(desc("count")).show() |
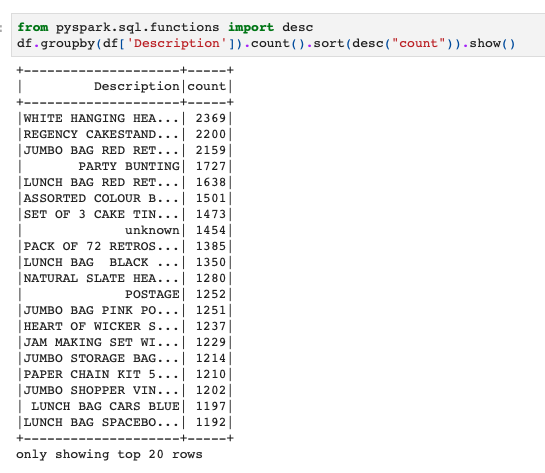
最後に、groupbyして計算したカウントを条件に使うパターンです。
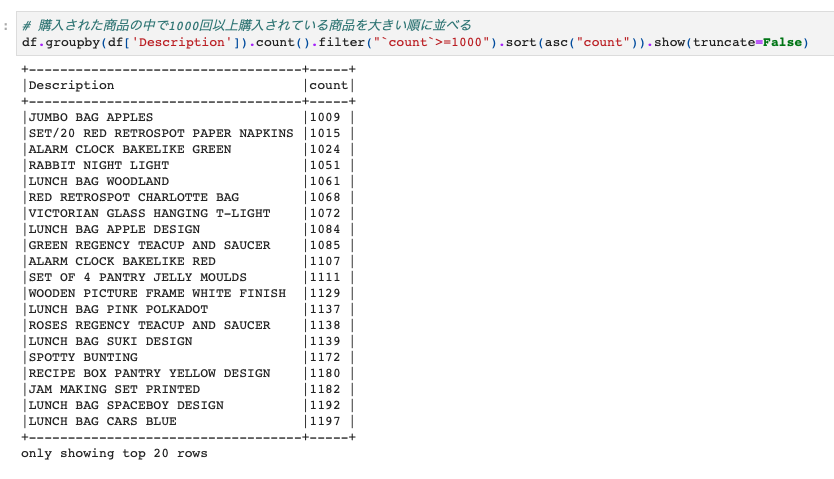
このようにしてPySparkでもgroupbyをしてSpark DataFrameに対して集計処理をかけることができます。
統計値の計算
集計処理は単に上のようにカウントしたりだけではなく、平均や最大値などの統計値を出す時にも使えます。
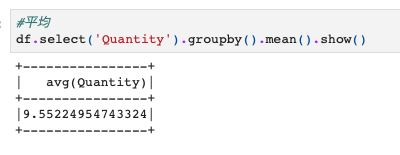
例えば、Quantity列でgroupbyして平均値を計算する例が以下になります。
|
1 2 |
#平均 df.select('Quantity').groupby().mean().show() |
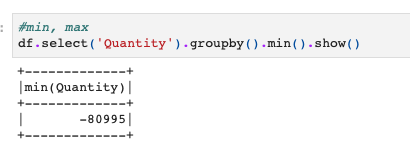
最小値や最大値も同様です。
|
1 2 |
#min, max df.select('Quantity').groupby().min().show() |
aggを使った集計計算
これまではgroupbyを使って集計処理をやりましたが、aggメソッドを使っても集計ができます。
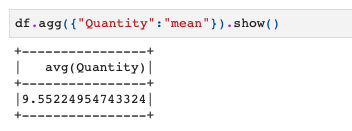
例えば、以下のようにQuantity列に対してgroupbyして平均を計算するコードはこのようにも書くことができます。
|
1 2 |
# agg df.agg({"Quantity":"mean"}).show() |
こちらの方が使い勝手がいいときもあるので、こちらの方法も覚えておくとよいかと思います!
PySparkの勉強法
もしPySparkをちゃんと学びたい方はUdemyのコースがおすすめです。日本語の書籍は古いやつしかないからです。。。
【Udemy】PySparkによる大規模データ処理手法と機械学習
英語でもよい方は英語のこのあたりがわかりやすいです。