データ分析を進める中で、データを集約したり、新たな形に変換したりすることがしばしばあります。Pandasでは、これらの操作を行うための強力なツールとして、ピボットテーブル、クロス集計、そしてデータの再構成を可能にするmeltやpivotメソッドが用意されています。この記事では、これらの機能を駆使して、データを効果的に操作する方法を解説します。さらに、クロス集計でよく使われるマルチインデックスの処理についても詳しく説明します。
ピボットテーブル
ピボットテーブルは、データを再構築して新たな形で集約するための強力なツールです。Pandasでは、pivot_tableメソッドを使うことで、データを簡単に集計・分析できます。
基本的なピボットテーブルの作成
以下の例では、店舗ごとの商品売上データをまとめて、月ごとの売上を集計します。
|
1 2 3 4 5 6 7 |
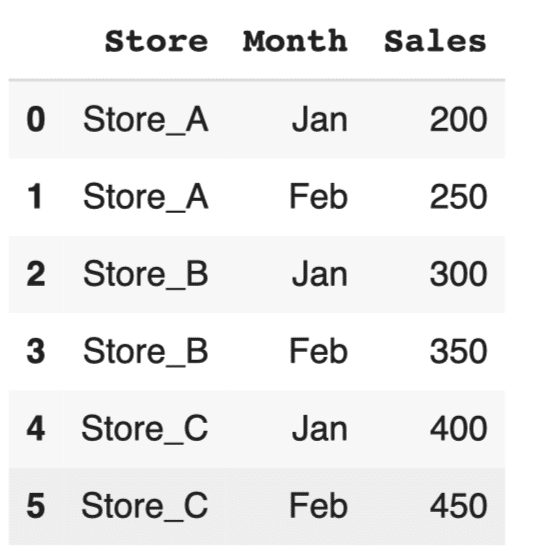
import pandas as pd #サンプルデータの作成 data = {'Store': ['Store_A', 'Store_A', 'Store_B', 'Store_B', 'Store_C', 'Store_C'], 'Month': ['Jan', 'Feb', 'Jan', 'Feb', 'Jan', 'Feb'], 'Sales': [200, 250, 300, 350, 400, 450]} df = pd.DataFrame(data) df |
|
1 2 3 |
#ピボットテーブルの作成 pivot_table = df.pivot_table(values='Sales', index='Store', columns='Month', aggfunc='sum') pivot_table |
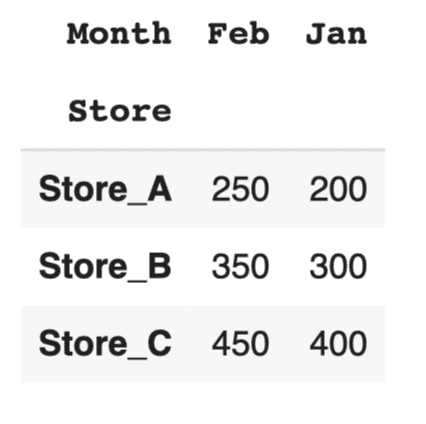
このコードでは、Storeを行ラベル、Monthを列ラベル、Salesを集計する値としてピボットテーブルを作成しています。これにより、店舗ごとの月別売上を簡単に集計できます。
複数の集計関数を使ったピボットテーブル
複数の集計方法でデータを分析することも可能です。例えば、売上の合計と平均を同時に集計できます。
|
1 2 3 |
#ピボットテーブルの作成(複数の集計) pivot_table_multi = df.pivot_table(values='Sales', index='Store', columns='Month', aggfunc=['sum', 'mean']) pivot_table_multi |
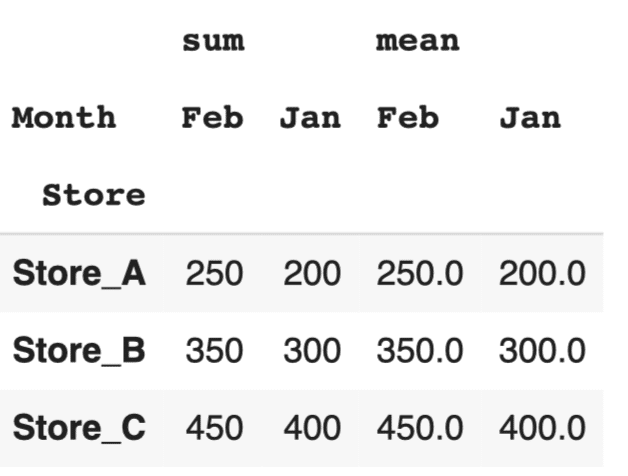
このコードでは、売上の合計と平均を同時に計算しています。これにより、データの多角的な分析が可能になります。
マルチインデックスの解除
結果を見ると、列が2段になっていますね。
これをマルチインデックスと呼びます。
マルチインデックスは、複数のインデックスレベルを持つデータ構造のことです。これにより、データの階層構造を視覚化でき、複雑な分析が可能になります。
Pandasのpivot_tableやgroupbyなどを使用したとき、列名が階層的(マルチインデックス)になる場合があります。この場合、列名がタプルの形式で格納されます。例えば、列名が ('A', 'sum') や ('B', 'mean') のようになることがあります。
扱いが少し面倒なので、マルチインデックスを戻す方法です。
マルチインデックスには行のインデックスと列のインデックスがありますが、行のインデックスでしたら、reset_index()をすれば大丈夫ですが、列に対しては効きません。
|
1 |
pivot_table_multi.reset_index() |
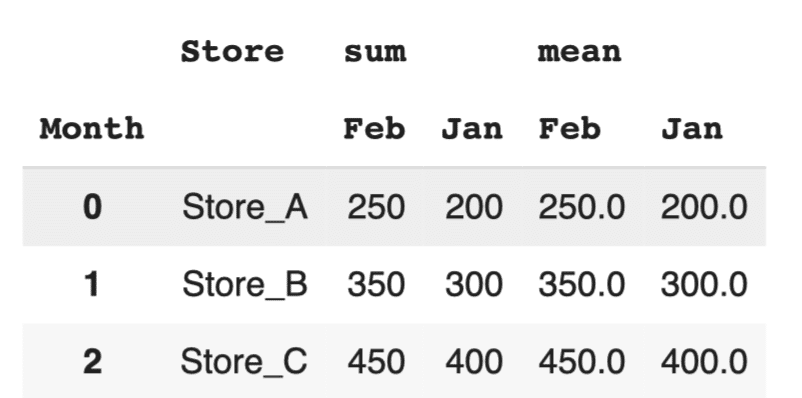
このコードでは、これらの階層的な列名を、例えば A_sum や B_mean といった、フラットで一意の列名に変換していきます。
|
1 2 3 4 |
# インデックスの解除 pivot_table_multi.columns = ['_'.join(col).strip() for col in pivot_table_multi.columns.values] display(pivot_table_multi) print(pivot_table_multi.columns) |
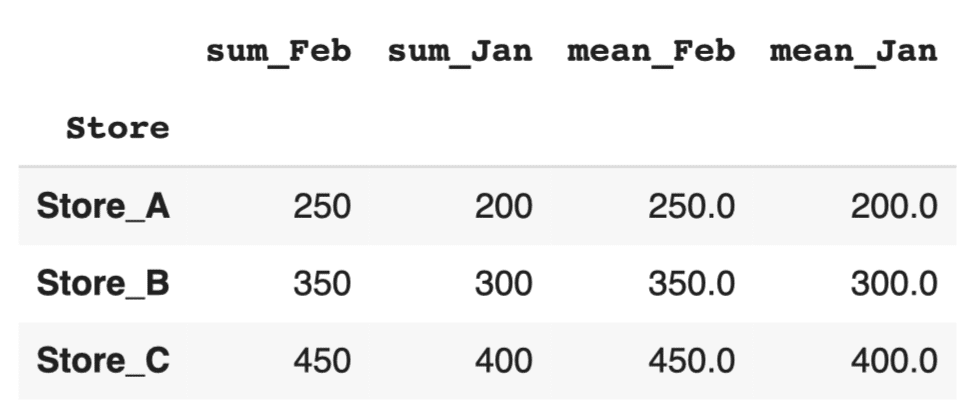
もしくはマルチインデックスのレベルごとの削除という方法もあります。
レベル指定による階層の除外
|
1 2 3 4 5 6 |
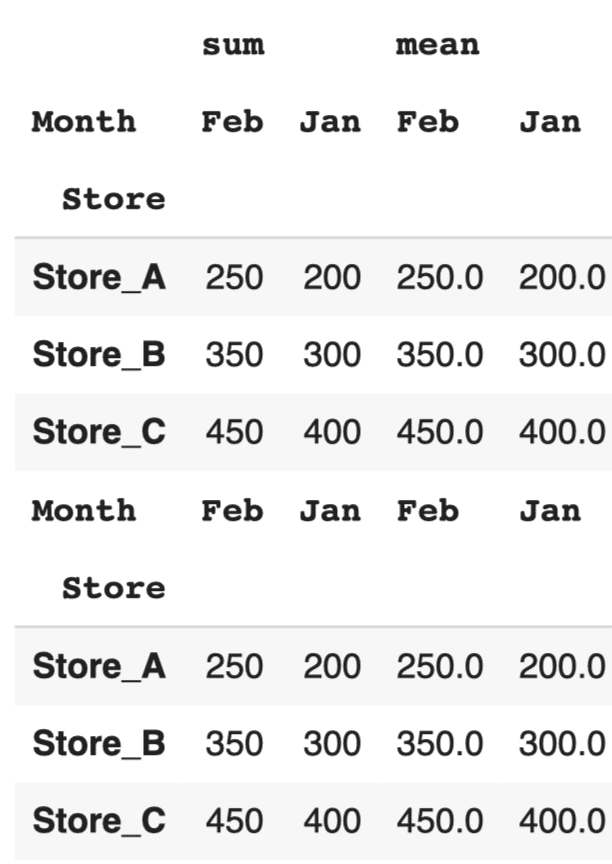
#レベル0のドロップ pivot_table_multi = df.pivot_table(values='Sales', index='Store', columns='Month', aggfunc=['sum', 'mean']) display(pivot_table_multi) pivot_table_multi.columns = pivot_table_multi.columns.droplevel(0) display(pivot_table_multi) print("===") |
|
1 2 3 4 5 |
#レベル1のドロップ pivot_table_multi = df.pivot_table(values='Sales', index='Store', columns='Month', aggfunc=['sum', 'mean']) display(pivot_table_multi) pivot_table_multi.columns = pivot_table_multi.columns.droplevel(1) display(pivot_table_multi) |
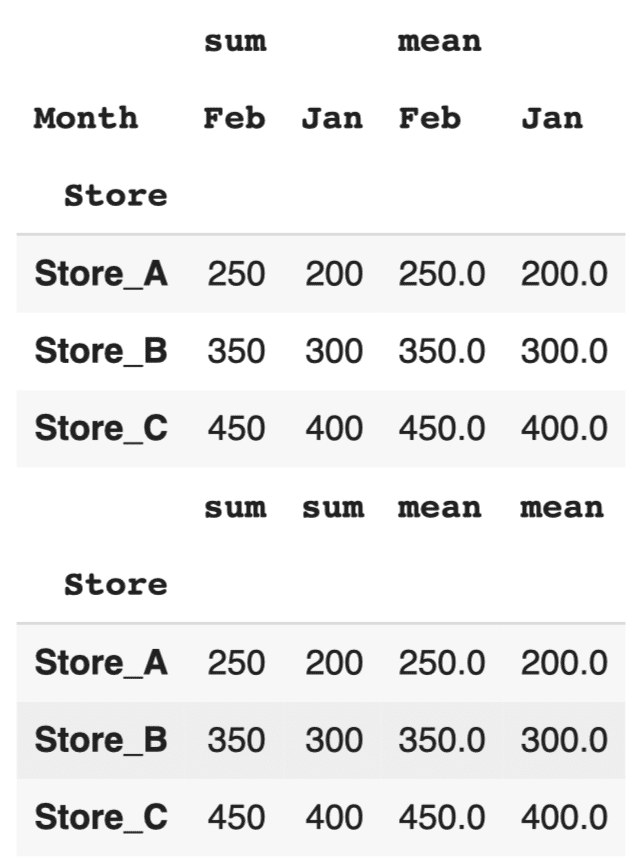
クロス集計
クロス集計(クロス集計表)は、2つ以上のカテゴリデータを組み合わせて集計する方法です。Pandasでは、crosstabメソッドを使ってクロス集計を簡単に作成できます。
基本的なクロス集計の作成
以下の例では、性別と購入商品のクロス集計を作成します。
|
1 2 3 4 5 |
# サンプルデータの作成 data = {'Gender': ['Male', 'Female', 'Female', 'Male', 'Female', 'Male'], 'Product': ['A', 'B', 'A', 'B', 'A', 'B']} df = pd.DataFrame(data) display(df) |
|
1 2 3 |
#クロス集計の作成 cross_tab = pd.crosstab(df['Gender'], df['Product']) cross_tab |

このコードでは、性別と購入商品のクロス集計を作成しています。これにより、各性別がどの商品をどれだけ購入したかが一目でわかります。
値の集計方法を指定したクロス集計
crosstabでは、集計方法が指定することもできます。
購入回数の合計ではなく、購入金額の合計を集計する場合には、valuesパラメータとaggfuncパラメータを使用します。
|
1 2 3 4 5 6 |
#購入金額の合計をクロス集計 #サンプルデータの作成 data = {'Gender': ['Male', 'Female', 'Female', 'Male', 'Female', 'Male'], 'Product': ['A', 'B', 'A', 'B', 'A', 'B'], 'Amount': [100, 150, 120, 130, 110, 140]} df = pd.DataFrame(data) cross_tab_amount = pd.crosstab(df['Gender'], df['Product'], values=df['Amount'], aggfunc='sum') cross_tab_amount |

クロス集計のパーセンテージ表示
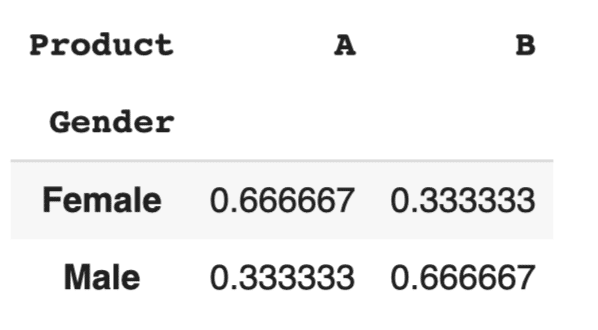
クロス集計の結果をパーセンテージで表示することも可能です。normalizeパラメータを使用すると、行ごと、列ごと、または全体の合計に対する割合を計算できます。
|
1 2 3 |
# クロス集計のパーセンテージ表示(行ごと) cross_tab_percent = pd.crosstab(df['Gender'], df['Product'], normalize='index') cross_tab_percent |
データの再構成:meltとpivot
Pandasでは、データフレームの形状を変更するためのメソッドとして、meltとpivotが用意されています。これらを使うことで、データの柔軟な再構成が可能になります。
meltメソッドの使い方
meltメソッドは、データフレームを縦持ちの形式に変換するために使います。
よくあるエクセルのような横持ち形式から、各観測値が独立した行を持つ縦持ち形式に変換する際に便利です。
|
1 2 3 4 5 6 |
# サンプルデータの作成 data = {'Store': ['Store_A', 'Store_B', 'Store_C'], 'Jan': [200, 300, 400], 'Feb': [250, 350, 450]} df = pd.DataFrame(data) display(df) |
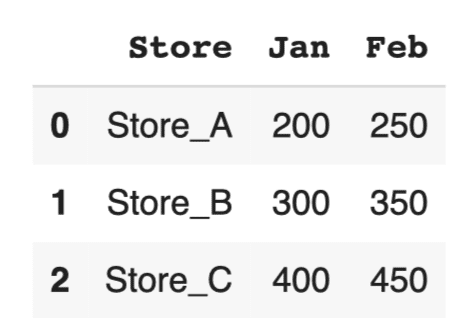
データのメルト(横持ち→縦持ち)
|
1 2 |
df_melted = df.melt(id_vars='Store', var_name='Month', value_name='Sales') df_melted |
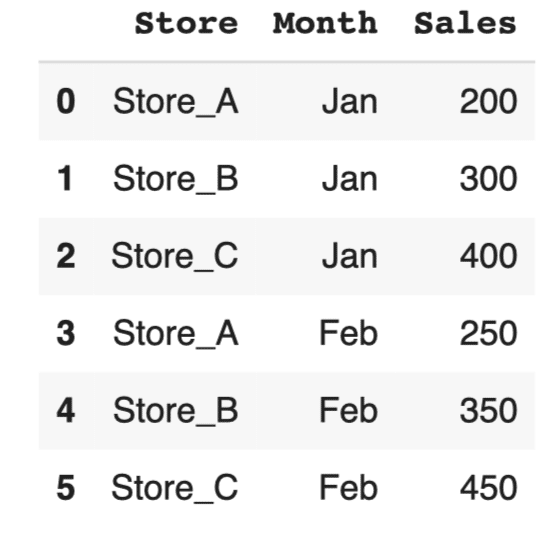
このコードでは、店舗ごとの売上データを横持ちから縦持ちに変換しています。
これにより、データを簡単に集計・分析できるようになります。
pivotメソッドの使い方
pivotメソッドは、meltメソッドの逆操作を行います。つまり、横持ちから縦持ちにデータを再構成します。
ピボット操作で元のデータ形式に戻す(縦持ち→横持ち)
|
1 2 |
df_pivoted = df_melted.pivot(index='Store', columns='Month', values='Sales') df_pivoted |
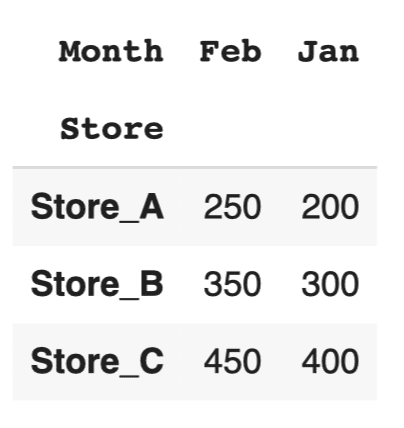
このコードでは、meltメソッドで縦持ちに変換したデータを、pivotメソッドを使って元の横持ち形式に戻しています。
まとめ
今回はピボットテーブルやクロス集計、そしてその結果現れるマルチインデックスの解除方法などを紹介しました。
分析をしていると、必ず使うものが1つはあると思います。
頭の片隅においておきたいところです。
======================================================
さらにデータサイエンスを学んでいきたいという方向けに「Pythonによるデータサイエンス」動画を提供しています。
基礎編・応用編それぞれ35時間以上の動画となっており、今なら50%OFFですので、ぜひチェックしてみてください!
>>>Pythonによるデータサイエンス基礎編
>>>Pythonによるデータサイエンス応用編