データ分析の際、特定の条件に基づいてデータを集計したり、新しい列を生成したりすることがよくあります。PandasとNumPyを使えば、これらの操作を効率的に行うことができます。特に、np.whereを使うと、条件に基づいてデータを簡単に操作することができます。この記事では、Pandasでの条件付き集計と、np.whereを使った条件付き列の生成方法について解説します。
np.whereの基本的な使い方
np.whereは、条件に応じて異なる値を返すことができるNumPyの関数です。Pandasのデータフレームと組み合わせて使用することで、条件に基づいて新しい列を生成する際に非常に便利です。
基本的な構文は以下の通りです:
|
1 |
np.where(条件, 条件がTrueの場合の値, 条件がFalseの場合の値) |
例えば、次のようにnp.whereを使って、ある数値が正なら1を、負なら-1を返す処理を行うことができます。
|
1 2 3 4 5 6 7 |
import numpy as np import pandas as pd # サンプルデータの作成 data = {'Number': [-5, 0, 5, 10, -10]} df = pd.DataFrame(data) df |

|
1 2 3 |
# np.whereを使って条件付き列を生成 df['Sign'] = np.where(df['Number'] > 0, 1, -1) df |
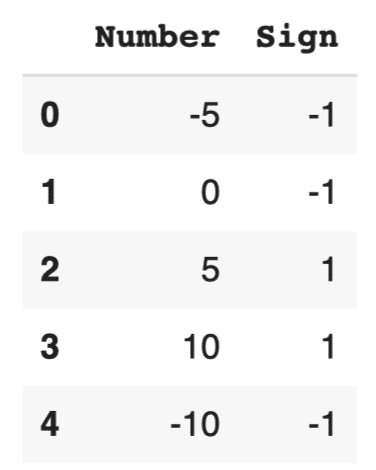
このコードでは、Number列の値が正の数であれば1、負の数であれば-1を新しいSign列に格納します。
複雑な条件を使った条件付き列の生成
np.whereを使うと、複数の条件を組み合わせた列の生成も簡単に行えます。例えば、以下の例では、数値が正なら「正」、0なら「ゼロ」、負なら「負」というラベルを付ける条件付き列を生成します。
|
1 2 3 |
# np.whereを使って複数条件を持つ列を生成 df['Category'] = np.where(df['Number'] > 0, '正',np.where(df['Number'] < 0, '負', 'ゼロ')) df |
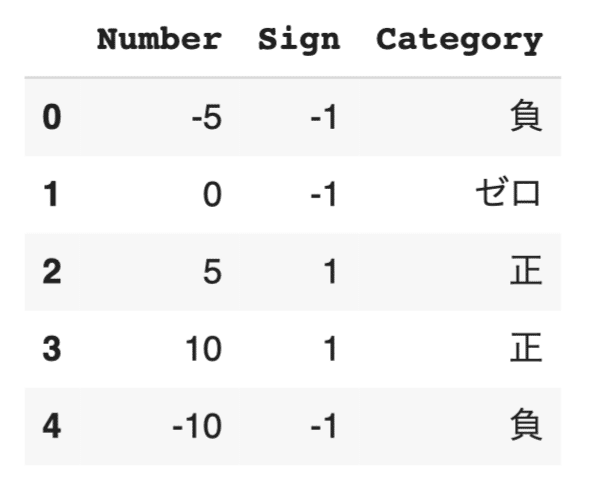
このコードでは、Number列の値が0より大きい場合は「正」、0より小さい場合は「負」、0の場合は「ゼロ」とラベル付けを行い、新しいCategory列に格納しています。
条件付きの集計
np.whereを使って条件付きの集計を行うこともできます。例えば、データフレームの特定の列が条件を満たす場合のみ、別の列の値を集計するようなケースです。
次の例では、ある商品の売上が100を超える場合に、その売上を集計し、それ以外は集計しないといった操作を行います。
|
1 2 3 4 5 |
# サンプルデータの作成 data = {'Product': ['A', 'B', 'C', 'D', 'E'], 'Sales': [150, 80, 120, 60, 180]} df = pd.DataFrame(data) df |
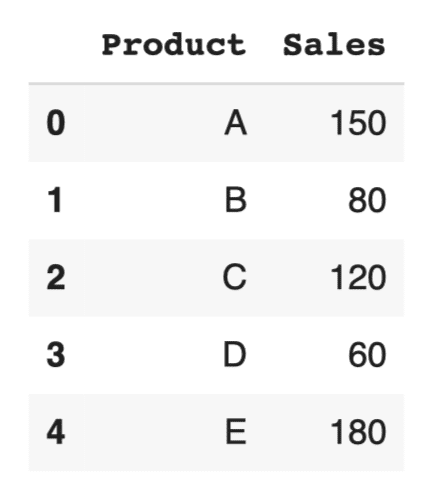
|
1 2 3 |
# 売上が100以上の商品の売上のみを集計 total_sales = df['Sales'].where(df['Sales'] >= 100).sum() print(f"Total sales for products with sales >= 100: {total_sales}") |
このコードでは、Sales列の値が100以上の商品の売上を合計し、その結果を表示しています。whereを使うことで、条件を満たさないデータはNaNになり、sum()を適用するとこれらのNaNは無視されます。
条件付きの列を集計に活用
また、np.whereで生成した条件付き列を使って、データを集計することも可能です。例えば、商品のカテゴリに応じて売上をグループ化し、集計を行う場合です。
|
1 2 3 4 |
# 条件に基づいてカテゴリを割り当てる df['Category'] = np.where(df['Sales'] >= 100, 'High', 'Low') category_sales = df.groupby('Category')['Sales'].sum() category_sales |
このコードでは、売上が100以上の商品を'High'、それ以外を'Low'としてカテゴリ分けし、それぞれのカテゴリごとに売上を集計しています。groupbyと組み合わせることで、条件に応じた柔軟な集計が可能です。
np.whereとapplyの違いと使い分け
Pandasにはnp.whereの他にも、applyメソッドを使ってカスタム関数を適用する方法もあります。これらは似たような目的で使われますが、それぞれ得意とする状況が異なります。
• np.where: 単純な条件分岐による値の割り当てに適しています。速度が速く、大量のデータに対して効率的に処理が可能です。
• apply: より複雑なロジックを必要とする場合に有効です。任意のPython関数を適用できるため、柔軟な操作が可能ですが、速度はnp.whereよりも遅くなることが多いです。
例えば、次のような複雑なロジックを適用する場合は、applyのほうが適しているかもしれません。
|
1 2 3 4 5 6 7 |
def categorize(sales): if sales >= 150: return 'High' elif 100 <= sales < 150: return 'Medium' else: return 'Low' |
|
1 2 |
df['Category'] = df['Sales'].apply(categorize) df |
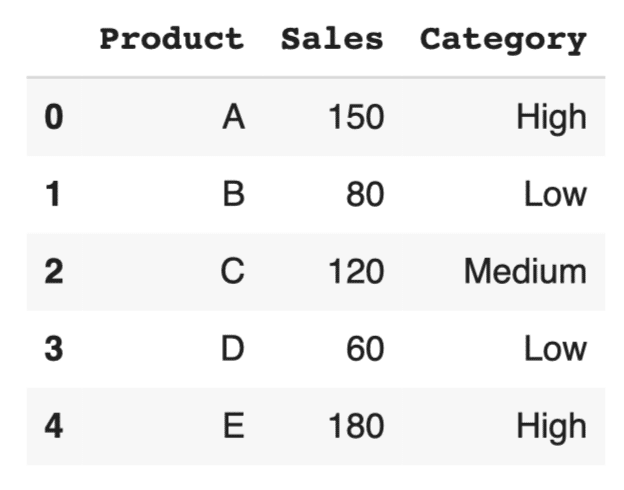
このコードでは、売上に基づいて'High'、'Medium'、'Low'のカテゴリを割り当てる複雑なロジックを実装しています。applyはこのような複雑な条件分岐を伴う場合に非常に便利です。
まとめ
Pandasとnp.whereを使った条件付き集計や列の生成は、データ分析の際に非常に役立つツールです。シンプルな条件分岐から複雑なロジックまで、これらの方法を使い分けることで、データ処理を効率的に行うことができます。この記事を参考に、実際のデータセットでnp.whereやapplyを活用してみてください!