Pandasは中小規模のデータセットに対して非常に効果的なデータ分析ツールですが、大規模データセットを処理する際にはメモリの使用量や処理速度が問題となります。
この記事では、Pandasを使用して大規模データセットを効果的に処理し、メモリを最適に使うためのテクニックを紹介します!
メモリ使用量の確認
データのメモリ使用量を理解することから始めましょう。
info()メソッドを使用して、DataFrameがどれだけのメモリを消費しているかを確認しましょう。
とりあえずサンプルのデータを読み込みす。一旦15万行くらい、50列の適当なデータです。
|
1 2 3 |
import pandas as pd df = pd.read_csv('large_dataset.csv') df |
|
1 |
df.info() |

メモリ使用量は57.9MBみたいです。
データ型の変更
Pandasでは列のデータ型がデフォルトで推測されますが、これを手動で調整することでメモリの使用量を減らすことが可能です。たとえば、小さい範囲の整数値のみを扱う場合、データ型をint64からint32へ変更することで、メモリ消費を削減できます。
|
1 2 3 |
df['col_0'] = df['col_0'].astype('int32') df['col_11'] = df['col_11'].astype('float32') df.info() |

2列だけデータ型を変えることで1MBほど変わりました。
ただし、データ型を変更する際は、情報の損失がないかを確認することが重要ですのでそこは注意してください。
チャンク処理
大規模なデータセットを一度にメモリに読み込む代わりに、チャンクとして小分けにして処理することでメモリ効率を向上させることができます。
read_csv()などのメソッドでchunksizeパラメータを設定し、データを分割して読み込んでみましょう。
とりあえず今のCSVは15万行ちょっとなので、これを5万行ごとに分割してしょりしてみましょう。
|
1 2 3 4 5 6 |
def process(chunk): print(chunk.head()) chunk_size = 50000 for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size): process(chunk) |

一度に全てを処理するのは難しくても、いくつかに分けて処理をすることはできますね!
不要な列の削除
こちらは単純です。使わない列は消しましょうということです!
|
1 2 3 |
unnecessary_columns = ["col_49", "col_48", "col_47"] df = df.drop(columns=unnecessary_columns) df.info() |
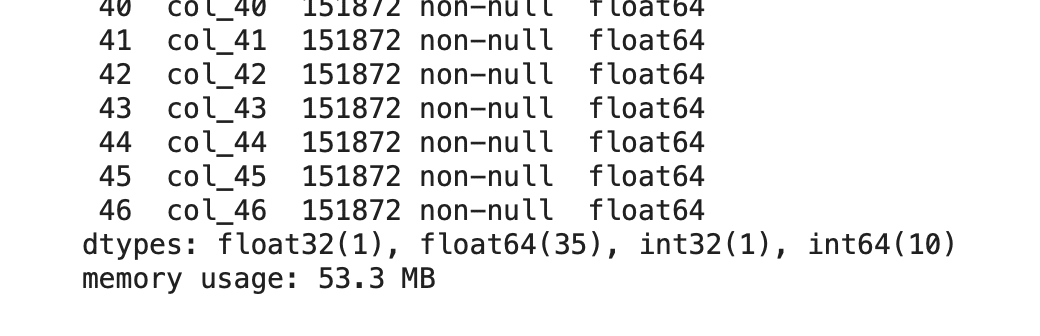
53.3MBまで減りました。ちょっと消すだけでも変わりますね!意外と使わない列って多かったりしますから、不要であれば消しましょう。
まとめ
こんな感じでチャンクに分けたり、データ型を変えたり、使わない列を削除したりすれば、少しではありますが使用するメモリを減らせます。