
PySparkのMLlibを使ったランダムフォレストによる分類予測をやってみます。
前回の記事ではPySparkによるロジスティック回帰をやったので、同じ分類予測をするランダムフォレストにも挑戦してみます。
前回同様、こちらの本を参考にさせていただきました。
Applied Data Science Using PySpark
使うデータはBankデータとして、その中の"y"列:定期預金したかどうかを目的変数としてモデリングをしていきたいと思います。
説明変数はデータを全部使うわけではなく一部とし、またパイプラインは使わずにやってみたいと思います。
PySpark MLlibでランダムフォレストによる分類
文字列データのインデックス化
初めはデータの読み込みですが、以前の記事でも紹介しているので今回は割愛します。
データの読み込みができたら、モデリングができるようにデータ処理をしていきます。
初めにdefault列がyes, noが入っているので、こちらをインデックス化して、defaultIndexという名前のカラムを作りましょう。
|
1 2 3 4 |
#String encoding -> default from pyspark.ml.feature import OneHotEncoder, StringIndexer default_index = StringIndexer(inputCol="default", outputCol="defaultIndex") data1 = default_index.fit(data).transform(data) |
インデックス化を実行する場合はfit, transformを行います。
以前の記事ではパイプライン化していたので、まとめてfit, transformしましたが、今回はパイプラインを使わずにやってみたいので、逐一実行していく必要があります。
目的変数の作成
目的変数は"y"列なのですが、yes, noで入っているので、こちらを0, 1に変換します。
|
1 2 3 |
#目的変数作成 from pyspark.sql.functions import lit, when, col data2 = data1.withColumn("y1", when(col("y") == 'yes' ,lit(1.0)).otherwise(lit(0.0))) |
モデリング用に説明変数をassemble
目的変数ができたので、説明変数も処理していきましょう。
説明変数はモデリングするためにassembleをします。
|
1 2 3 4 |
#データ作成 from pyspark.ml.feature import VectorAssembler assemble = VectorAssembler(inputCols=features, outputCol='features') df = assemble.transform(use_df) |
訓練・テストデータに分割
モデリングは訓練データを用いて行いますから、訓練データとテストデータに7:3で分けてみたいと思います。
今回はシンプルにrandomsplitです。層化とかは考えません。
|
1 2 |
# train test split train_df, test_df = df.randomSplit([0.7, 0.3], seed = 123) |
ランダムフォレストによるモデリングと推論
これでモデリングをする準備ができましたので、モデリングを行います。
ランダムフォレストは分類だけでなく数値予測もできるのですが、今回は分類予測なのでRandomForestClassifierを使います。
|
1 2 3 4 5 |
from pyspark.ml.classification import RandomForestClassifier clf = RandomForestClassifier(featuresCol='features', labelCol='y1', impurity='gini') clf_model = clf.fit(train_df) pred_train = clf_model.transform(train_df) pred_train.show() |
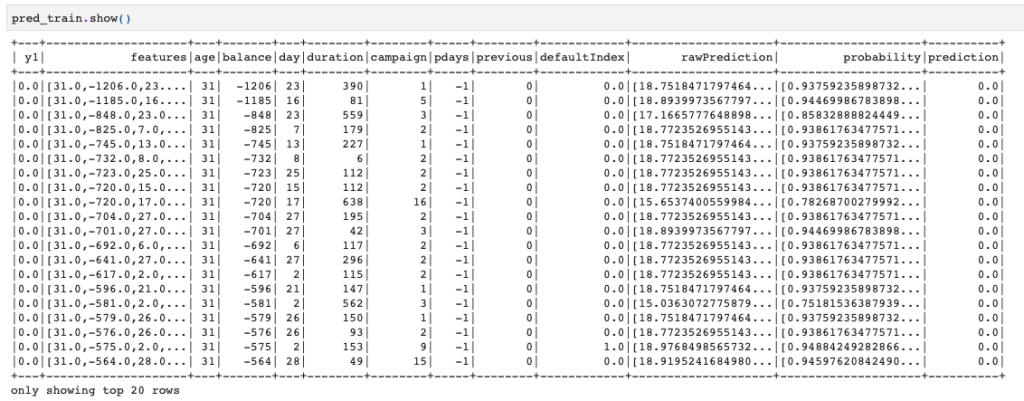
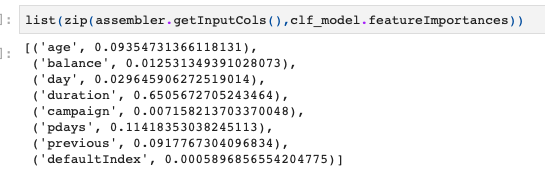
一応、ランダムフォレストの重要度を出しておくとこんな感じになりました。
durationの重要度が高いんですね。
精度評価:AUCの計算
訓練データでの予測結果を使ってAUCを計算してみます。
AUC計算は一旦PysparkのデータフレームからPandasのデータフレームに変換して実行してもよいのですが、今回はpysparkのままでやってみます。
|
1 2 3 4 |
from pyspark.ml.evaluation import BinaryClassificationEvaluator evaluator = BinaryClassificationEvaluator(labelCol='y1') AUC = evaluator.evaluate(pred_train) AUC |
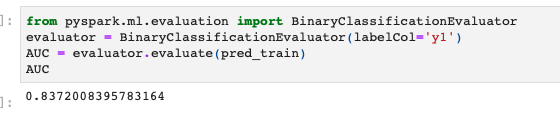
これで訓練データを使ったモデリング関連の処理が完了です!
テストデータでの推論とAUC計算
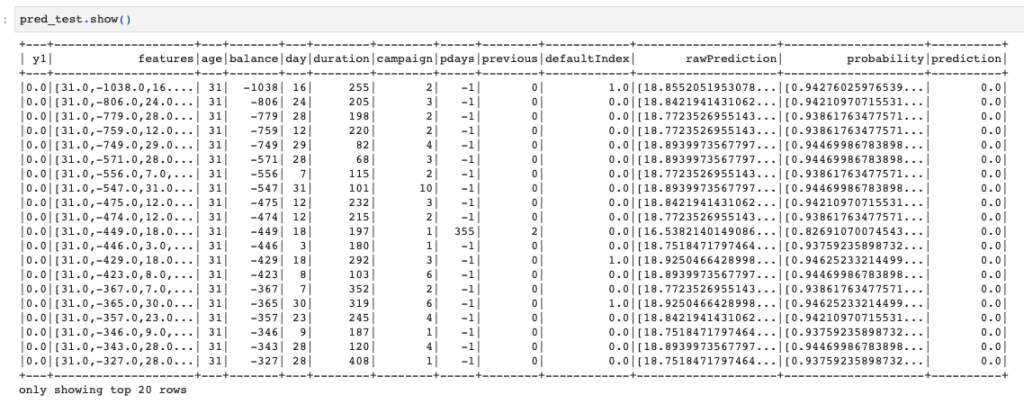
ではテストデータを使って推論とAUC計算をしてみます。
|
1 2 |
pred_test = clf_model.transform(test_df) pred_test.show() |
|
1 2 3 4 |
from pyspark.ml.evaluation import BinaryClassificationEvaluator evaluator = BinaryClassificationEvaluator(labelCol='y1') AUC = evaluator.evaluate(pred_test) AUC |
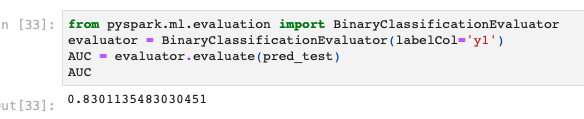
AUCは若干下がりましたが、意外と高いままですね。


