
PySparkのMLlibを使ったkmeansによるクラスタリングをやってみたいと思います。
過去の記事ではPySparkによる線形重回帰やロジスティック回帰など数値予測や分類予測を行いましたので、今回はクラスタリングにも挑戦してみます。
前回同様、こちらの本を参考にさせていただきました。
Applied Data Science Using PySpark
今回使うデータはお馴染みのIrisデータです。この中の"variety"列:Irisの種類の名前でクラスタリングをしていきたいと思います。
変数は、sepal_length, sepal_width, petal_length, petal_widthの4つを使います。
PySpark MLlibでkmeansによるクラスタリング
クラスタリング用に変数をassemble
まずはデータを読み込みます。こんなデータになっています。
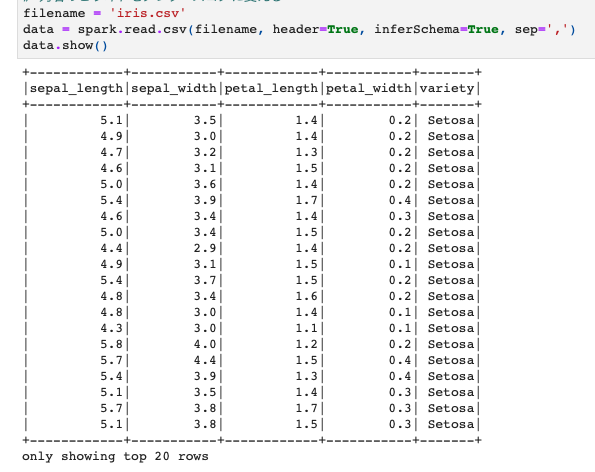
クラスタリングをする対象となるvarietyの種類をカウントするとこんな感じで50レコードずつ入っているようです。
そしてクラスタリングを行うために変数をassembleをします。
今回はこのデータに入っている全てのデータを使うので、全てをひとまとめにし、featuresというカラムをつくります。
パイプラインは今回は使わずにやりますので、最後にtransformします。
|
1 2 3 4 5 |
#assembler from pyspark.ml.feature import VectorAssembler assemble = VectorAssembler(inputCols=['sepal_length','sepal_width','petal_length','petal_width'] , outputCol='features') pred = assemble.transform(df) |
kmeanクラスタリングの実行
さて、kmeansクラスタリングを実行するわけですが、kの値を決めなければいけません。
よくある手としては各kに対するシルエット係数を計算したり、エルボー法と呼ばれる手法を用いるなどがあります。
これらについては別の機会に記事を書いてみたいと思いますが、他にも分かりやすい解説があるので、そちらを参照してください。
とりあえず今回は正解がわかっているので、その正解にもとづいてkmeansのk=3の場合をやってみたいと思います(Irisは3種類ということがわかっているため)。
|
1 2 3 4 5 |
#k=3の場合 kmeans = KMeans().setK(3).setSeed(1) model = kmeans.fit(pred) predictions = model.transform(pred) predictions.show() |

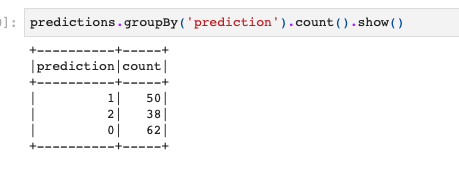
さて、これでクラスタリングができたのでその結果も確認しておきます。
とりあえず、各クラスターの数だけ。
|
1 |
predictions.groupBy('prediction').count().show() |
一応k=3でシルエット係数の計算もしてみます。
本来はk=1~10とかまで計算してみて、その変化を確認するのがよいと思います。
|
1 2 3 4 |
evaluator = ClusteringEvaluator() silhouette = evaluator.evaluate(predictions) print("K={}".format(k)) print("シルエット係数:{}" .format(str(silhouette))) |
![]()
と、こんな感じでPySparkでもkmeanによるクラスタリングをとりあえず行うことができました。
Irisのデータを使っているのでクラスタ数もわかっていますし、データ量も少ないのでこの例ではPySparkを使うこともありませんが、使うべき場面で使えるようになっておくと良いですね。


