
こんにちわ!
今回の記事ではPySparkでCSVファイルを読み込む方法を紹介したいと思います。
みんな大好きPandasではread_csvで読み込むことができますが、PySparkでも似たような感じで簡単にCSVファイルを読み込み、Spark DataFrameに格納することができます。
読み込み方法としてはスキーマを指定して読み込む方法と、スキーマは自動で推定してもらう方法の大きく2種類があると思いますので、それぞれの方法でデータを読みこんでみます。
では始めましょう!
参考にしたのはこちらです。
Applied Data Science Using PySpark
日本語だとこちら。
入門PySpark
read csvでスキーマ指定せず読み込む
まずはスキーマを指定せずに読みこんでみます。
試しに読み込むデータはbankデータにしてみます。
bankデータに興味がある方は、こちらを見てみてくださいね。
https://archive.ics.uci.edu/ml/datasets/bank+marketing
こちらはUCIのWEBサイトですが、kaggleからもダウンロードすることができるようです。
さて、まずはSparkSessionをimportしてSparkSessionを立ち上げます。
|
1 2 3 4 5 6 |
from pyspark.sql import SparkSession filename = 'bank/bank-full.csv' spark = SparkSession.builder \ .master("local") \ .appName("app") \ .getOrCreate() |
これでSparkSessionを立ち上げられたので、このあとは下のコードのようにspark.read.csvとして、ファイル名やヘッダー情報などを入力し、"inferSchema=True"としてやるだけです。
とても簡単ですね。
|
1 2 |
data = spark.read.csv(filename, header=True, inferSchema=True, sep=';') data.show() |
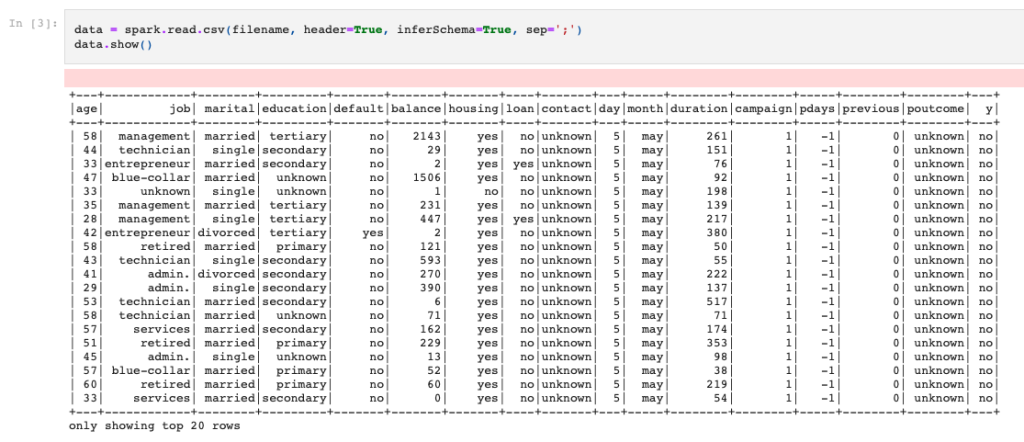
これで結果をSpark DataFrameに格納することができて、show()してみるとこのようにちゃんと読み込めていることがわかるかと思います。

ちなみにdtypesするとこのようにいい感じに自動でスキーマを推測してくれていることがわかるかと思います。
厳密にやりたい場合はこれからやる方法で、読み込み時にスキーマ指定をしておいた方が良いかと思いますが、それほどこだわりがないのであれば、このように自動でスキーマを決めてもらっても大丈夫ではないでしょうか。
CSVファイル読み込み時にスキーマを指定する方法
では、CSVファイルを読み込むときに、スキーマも指定する方法を紹介しておきます。
自動でスキーマを決めるときは"inferSchema=True"にしましたが、手動でスキーマを指定する場合は"inferSchema=False"にし、schemaを手動で設定していきます。
こちらのデータはOnline Retailのデータにし、スキーマは適当にString, Integer, Date, Floatなどそれぞれ個別にStructFeildで指定していきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType, DateType schema = StructType([ StructField("InvoiceNo", StringType(), False), StructField("StockCode", StringType(), False), StructField("Description", StringType(), False), StructField("Quantity", IntegerType(), False), StructField("InvoiceDate", DateType(), False), StructField("UnitPrice", FloatType(), False), StructField("CustomerID", StringType(), False), StructField("Country", StringType(), False) ]) |
スキーマ情報をschemaという変数に入れたので、こちらを使ってreadしてみます。
今度はread.formatでCSVを指定し、loadの中でschemaを先ほど作成したschema変数を指定します。
|
1 2 3 4 |
df = spark.read.format("csv") \ .option("header", "True") \ .option("sep", ",") \ .load("./data/Online_Retail.csv", schema=schema) |
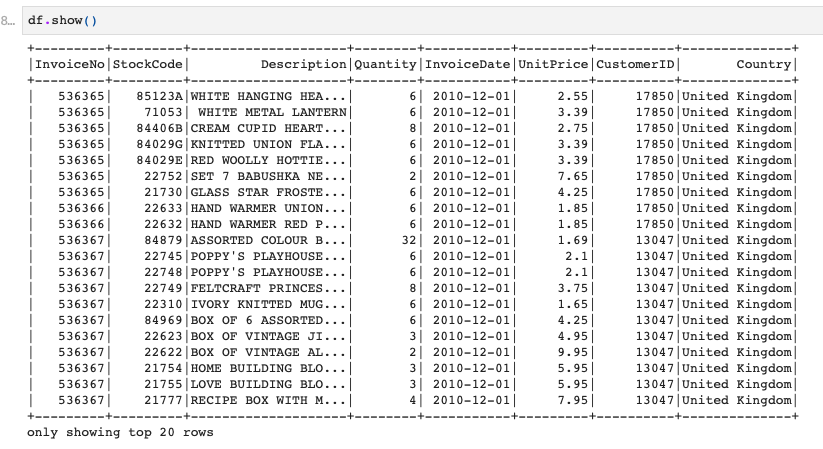
これでCSVファイルのデータ読み込みが完了し、Spark DataFrameに格納できています。
一応中身とスキーマを確認してみましょう。

はい、このようにちゃんとスキーマの指定通りになっていますね!
こんな感じでスキーマを指定するパターンとしないパターンで読み込むことができました!
-

-
データサイエンティストとして3年間で3社経験した僕の転職体験談まとめ
こんにちわ、サトシです。33歳です。 今回は、データサイエンティストの3年間に3社で働いた僕が、データサイエンティストとしての転職活動についてまとめて書きたいと思います。 これまでSE→博士研究員→ポ ...
PySparkの勉強法
もしPySparkをちゃんと学びたい方はUdemyのコースがおすすめです。日本語の書籍は古いやつしかないからです。。。
【Udemy】PySparkによる大規模データ処理手法と機械学習
英語でもよい方は英語のこのあたりがわかりやすいです。

