この記事では、Pandasを用いた時系列データの処理と解析について紹介していきます。
目次
PandasにおけるDateTime操作の基本
Pandasでは、時系列データを効果的に操作するためのさまざまなメソッドが提供されています。時系列データを扱う際の基本的なステップは、まずデータを適切な日時形式に変換することです。Pandasではpd.to_datetime関数を用いて、この操作を簡単に行うことができます。
Datetime型への変換
まず、データフレームの文字列形式の日付をpd.to_datetimeを使ってDatetime型に変換します。Datetime型とは、日付と時間を含むデータ型で、Pandasではyyyy-mm-dd hh:mm:ssの形式で扱われます。この形式は、年(yyyy)、月(mm)、日(dd)、時間(hh)、分(mm)、秒(ss)を示しており、時間の精度を高めるために非常に便利です。
サンプルデータの作成
|
1 2 3 4 |
data = {'date': ['2023-08-01 14:30:00', '2023-08-02 15:45:00', '2023-08-03 16:00:00', '2023-08-04 18:30:00', '2023-08-05 20:00:00'], 'value': [10, 20, 30, 40, 50]} df = pd.DataFrame(data) |
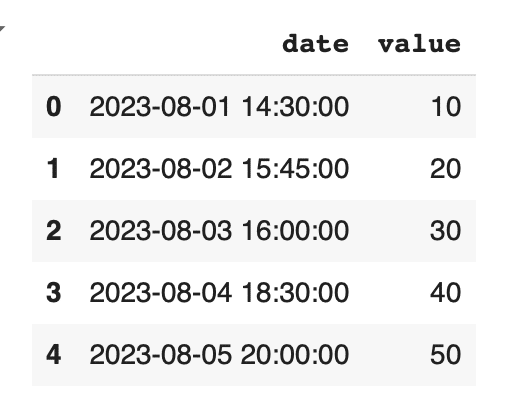
日付をDatetime型に変換
|
1 2 |
df['date'] = pd.to_datetime(df['date']) print(df) |
上記のコードでは、pd.to_datetimeを使用して、文字列として格納されている日付をPandasのDatetime型に変換しています。この変換により、日時を用いた計算や操作が容易になります。また、Datetime型を使用することで、年、月、日だけでなく、時間、分、秒といったより詳細な情報も扱うことができます。
Datetime型の特定フォーマットへの変換
場合によっては、Datetime型を特定のフォーマットに変換する必要があるかもしれません。例えば、年と月だけが必要な場合や、時刻だけを取り出したい場合などです。Pandasでは、strftimeメソッドを使用して、Datetime型を指定したフォーマットの文字列に変換できます。
年と月のみを取り出す
|
1 |
df['year_month'] = df['date'].dt.strftime('%Y-%m') |
時間のみを取り出す
|
1 2 |
df['time'] = df['date'].dt.strftime('%H:%M:%S') print(df) |
このコードでは、strftime('%Y-%m')を使用して、Datetime型から年と月だけを取り出し、strftime('%H:%M:%S')を使用して、時刻だけを取り出しています。このように、Datetime型のフォーマットを自由にカスタマイズすることができます。
Datetime型からの情報抽出
Datetime型に変換されたデータからは、年(year)、月(month)、日(day)、曜日(weekday)などの情報を簡単に取り出すことができます。これにより、データを基に様々な分析を行うことが可能です。
Datetime型から年、月、日、時間、分を取り出す
|
1 2 3 4 5 6 7 |
df['year'] = df['date'].dt.year df['month'] = df['date'].dt.month df['day'] = df['date'].dt.day df['hour'] = df['date'].dt.hour df['minute'] = df['date'].dt.minute df['weekday'] = df['date'].dt.weekday # 月曜日が0、日曜日が6 print(df) |
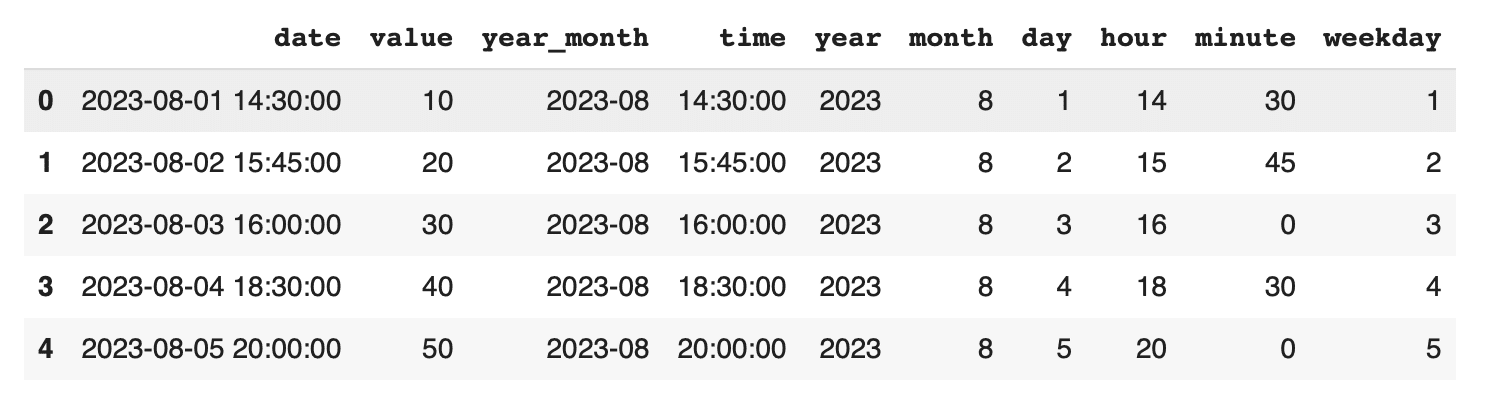
このコードでは、df['date'].dt.yearのように.dtアクセサを使用して、年、月、日、時間、分、曜日の情報を抽出しています。特に、時間や分の情報は、特定の時間帯の傾向を分析する際に非常に有用です。
特定の期間を抽出する
Datetime型を用いることで、特定の期間のデータを抽出することも簡単にできます。日時形式のデータを活用して、特定の時間帯や日付範囲でデータをフィルタリングできます。
特定日時以降のデータを抽出
|
1 2 |
filtered_df = df[df['date'] >= '2023-08-02 15:00:00'] print(filtered_df) |
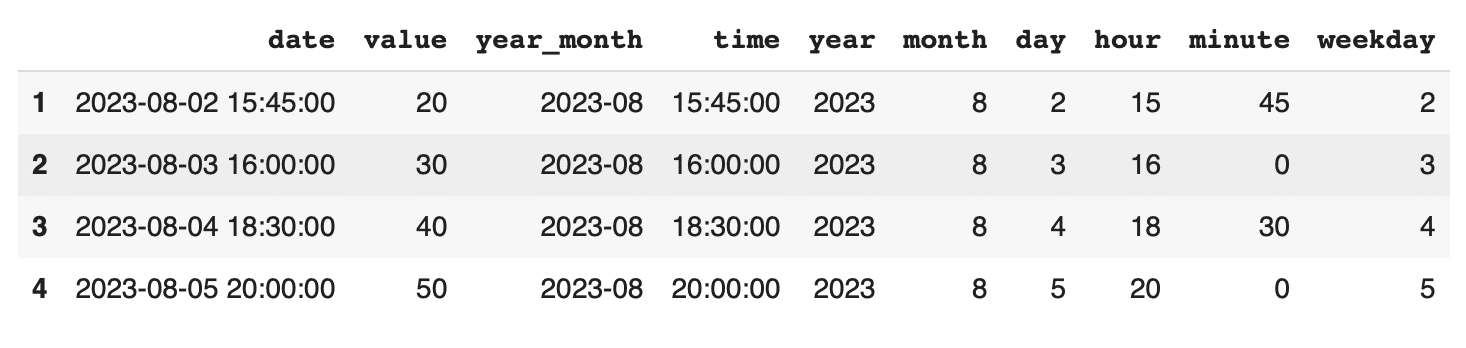
このコードでは、2023年8月2日15時以降のデータのみを抽出しています。条件を指定してデータをフィルタリングすることで、特定の期間の分析や処理が効率的に行えます。
時系列データのリサンプリング(resample)
時系列データの解析では、異なる時間間隔でデータを集約することが頻繁に求められます。Pandasではresampleメソッドを用いて、データの頻度を変えることができます。例えば、日次データを月次データに変換するなどの操作が可能です。
データを日次から2日毎にリサンプリング
|
1 2 |
df_resampled = df.resample('2D', on='date').sum() print(df_resampled) |
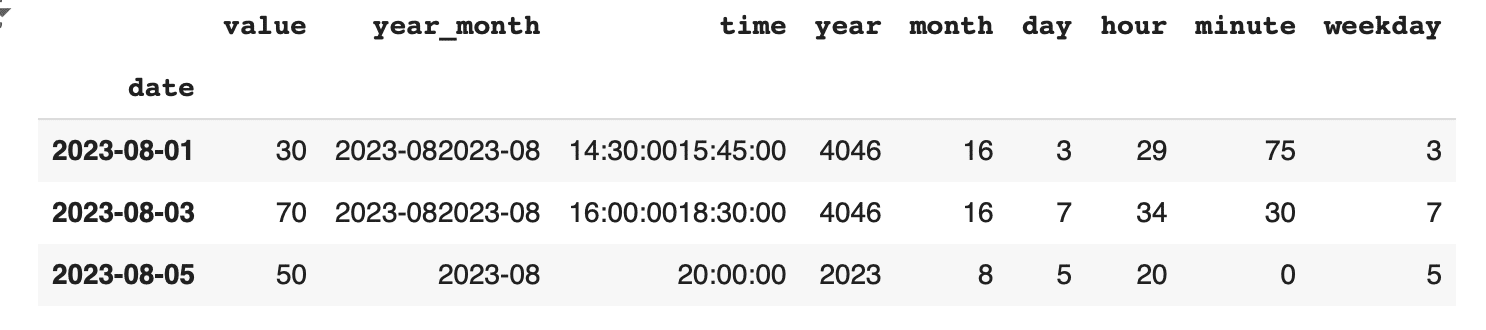
このコードでは、元々日次のデータを2日毎にリサンプリングし、各期間内の合計値を計算しています。resampleメソッドでは、'D'や'M'のような頻度オプションを指定することで、リサンプリングの粒度を柔軟に設定できます。
時系列データのシフト(shift)
時系列データの解析において、前日や翌日のデータと比較することがよくあります。Pandasではshiftメソッドを使用して、データを前後にシフトさせることができます。これにより、例えば、前日との差分を計算することが可能になります。
前日との差分を計算
|
1 2 3 |
df['previous_value'] = df['value'].shift(1) df['difference'] = df['value'] - df['previous_value'] print(df) |
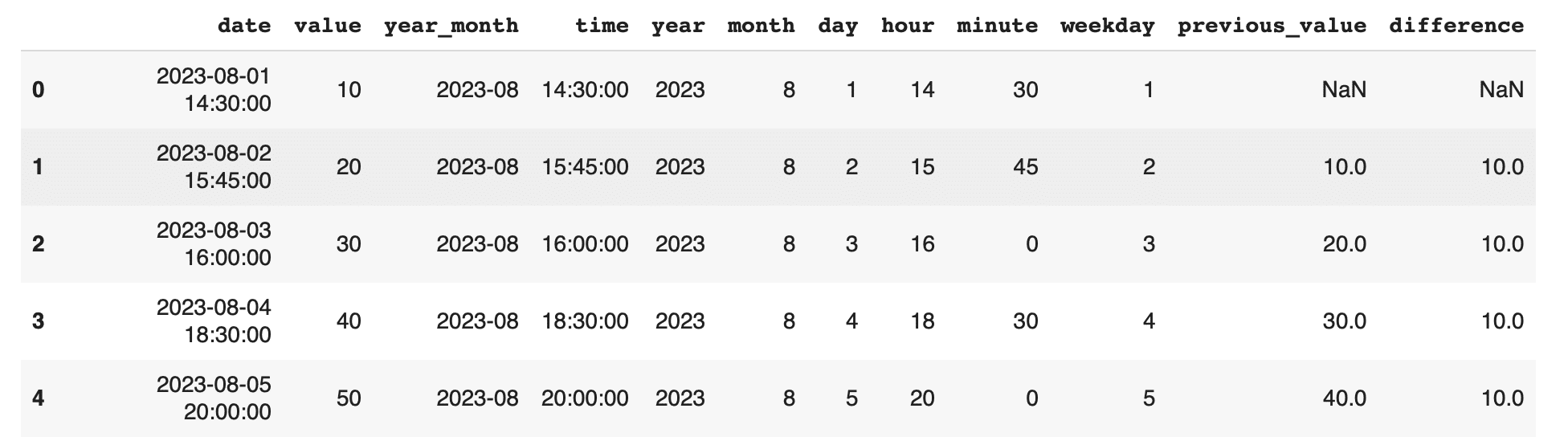
上記の例では、shift(1)を用いて前日のデータを取得し、現日のデータとの差分を計算しています。このように、shiftメソッドは時系列データに対する遅延データの操作や移動平均の計算に非常に有用です。
応用例:移動平均の計算
時系列データの分析でよく行われるのが、移動平均の計算です。これは、一定期間のデータの平均を計算し、時系列データのトレンドを滑らかにする手法です。Pandasでは、rollingメソッドとmeanメソッドを組み合わせることで、簡単に移動平均を計算することができます。
3日間の移動平均を計算
|
1 2 |
df['moving_average'] = df['value'].rolling(window=3).mean() print(df) |

この例では、rolling(window=3)を使用して3日間の移動平均を計算しています。移動平均は、データのノイズを減らし、全体的な傾向を把握するのに役立ちます。
移動平均の中央の日付を変える場合は、center=Trueを入れます。
|
1 2 |
df['moving_average'] = df['value'].rolling(window=3, center=True).mean() df |

まとめ
pd.to_datetime、resample、shiftといった基本的なメソッドを活用することで、時系列データの操作が格段にやりやすくなります。
特にDatetime型のyyyy-mm-dd hh:mm:ss形式を活用することで、日付や時間に関連する複雑な分析が可能になりますので、ぜひ試してみてくださいね!
======================================================
さらにデータサイエンスを学んでいきたいという方向けに「Pythonによるデータサイエンス」動画を提供しています。
基礎編・応用編それぞれ35時間以上の動画となっており、今なら50%OFFですので、ぜひチェックしてみてください!
>>>Pythonによるデータサイエンス基礎編
>>>Pythonによるデータサイエンス応用編