時系列データのデータセットでは欠損値(ギャップ)がしばしば発生することがあります。
これらのギャップを適切に処理しないと、データ分析やモデルの予測精度に悪影響を及ぼす可能性がありますから、こうしたギャップを埋めることが必要で、特に便利なのがinterpolateメソッドです。
この記事では、Pandasで時系列データのギャップフィルリングの方法について、interpolateを使った方法を紹介します。
interpolateメソッドとは?
interpolateは、欠損値を補完するためにPandasが提供するメソッドです。このメソッドは、既存のデータポイントを利用して欠損値を推測し、埋める役割を果たします。interpolateメソッドは、線形補間や時間ベースの補間など、さまざまな補間方法をサポートしており、データの特性に応じて適切な方法を選択できます。
基本的なinterpolateの使い方
まずは、interpolateメソッドの基本的な使い方を見てみましょう。ここでは、簡単な時系列データを用いて、線形補間によるギャップの埋め方を紹介します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import pandas as pd import numpy as np # サンプルデータの作成 date_rng = pd.date_range(start='2023-08-01', end='2023-08-10', freq='D') data = {'date': date_rng, 'value': [10, np.nan, 30, np.nan, 50, 40, np.nan, 70, 60, 80]} df = pd.DataFrame(data) df['date'] = pd.to_datetime(df['date']) df.set_index('date', inplace=True) # 線形補間によるギャップフィルリング df['value_filled'] = df['value'].interpolate() df |
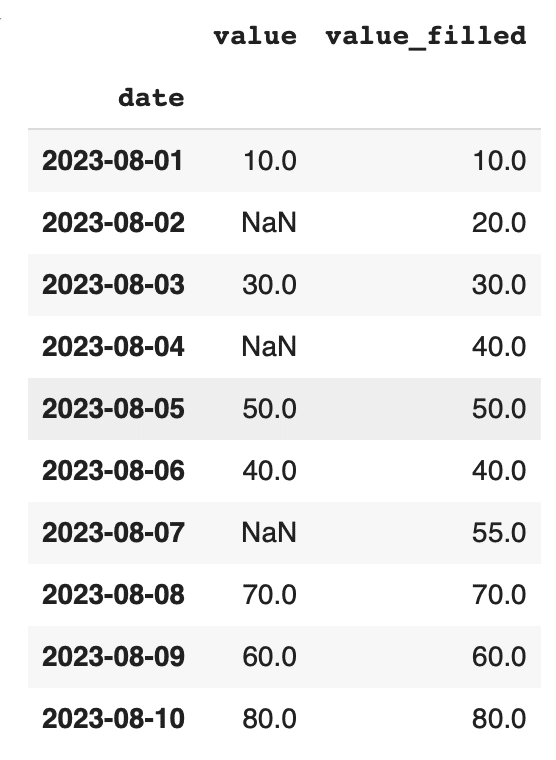
このコードでは、value列に欠損値を含むデータフレームを作成し、interpolateメソッドを使って線形補間を行っています。
interpolateメソッドは、欠損値の前後のデータポイントから線形的に補完された値を計算します。上記の例では、2023-08-02の値は20.0、2023-08-04の値は40.0として補完されています。
時間ベースの補間
線形補間以外にも、Pandasのinterpolateメソッドでは時間に基づいた補間が可能です。これは、データのインデックスが日時型(DatetimeIndex)の場合に特に有用です。
|
1 2 |
df['value_time_filled'] = df['value'].interpolate(method='time') df |
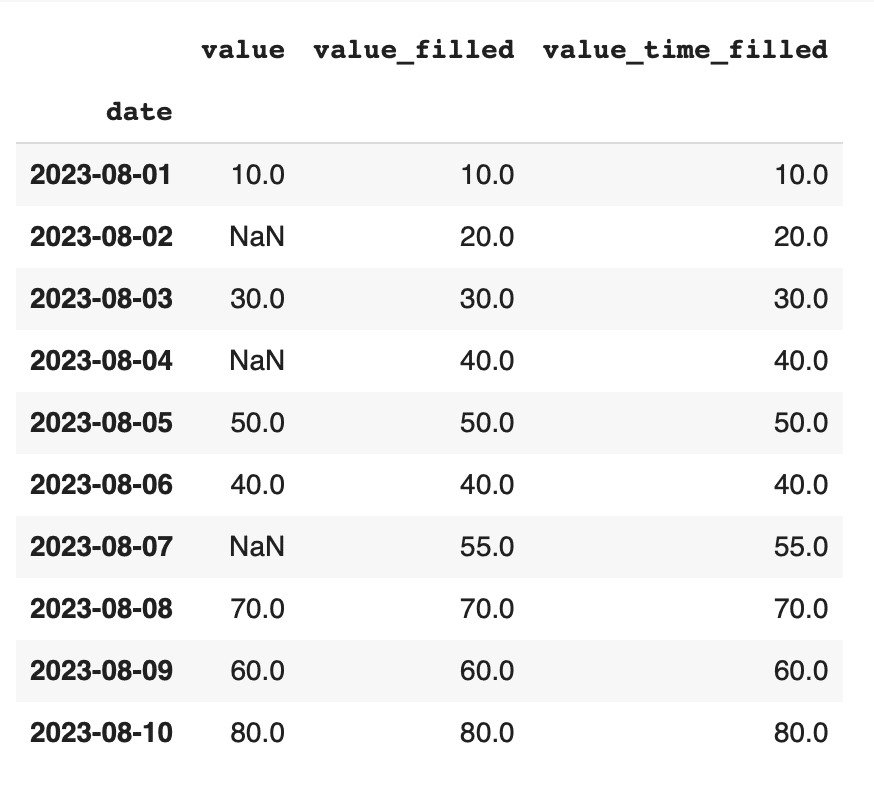
このコードでは、method='time'を指定して時間ベースの補間を行っています。時間ベースの補間では、データポイントの時間差を考慮して欠損値を補完します。これにより、時間に依存する変動を考慮した補間が可能になります。
スプライン補間
スプライン補間は、欠損値を補完するための高度な方法の一つです。
スプラインは、関数を小さな区間ごとに滑らかに接続した曲線で、非線形のデータに対して適切な補間を行うことができます。
Pandasでは、interpolateメソッドでmethod='spline'を指定し、orderパラメータでスプラインの次数を設定することでスプライン補間を行うことができます。
3次スプライン補間によるギャップフィルリング
|
1 2 |
df['value_spline_filled'] = df['value'].interpolate(method='spline', order=3) df |
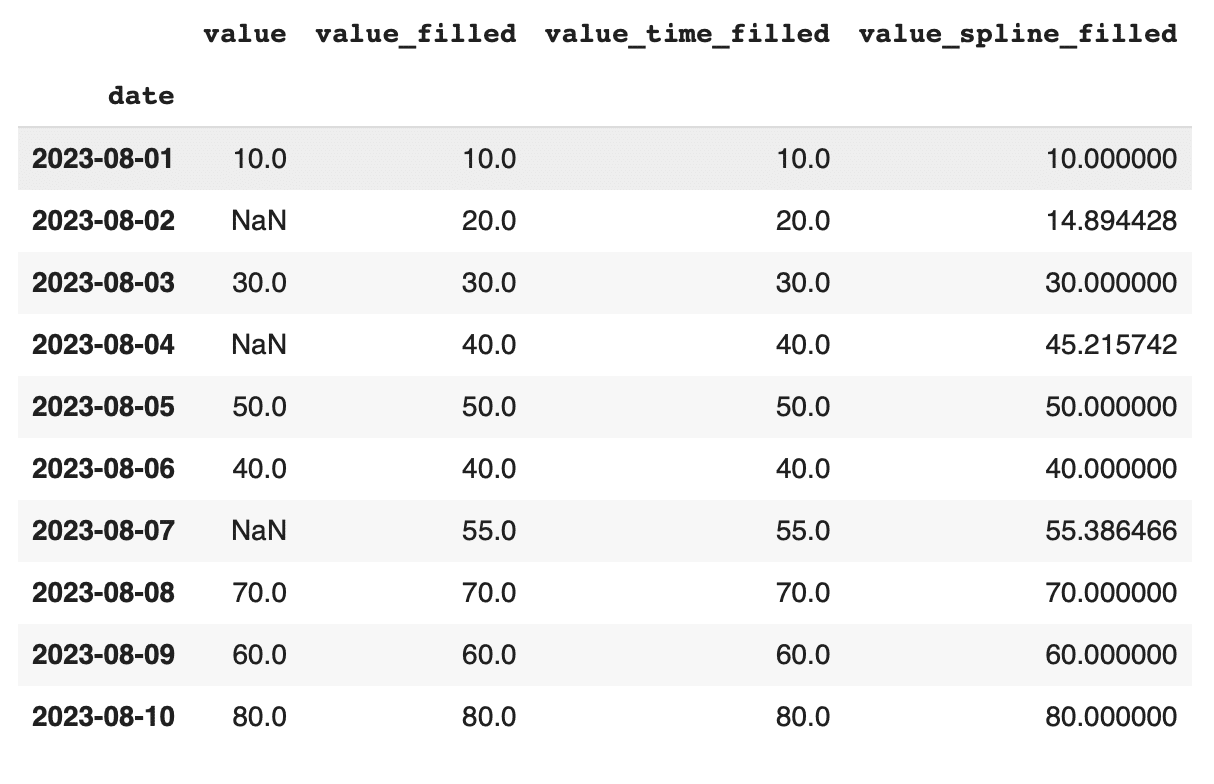
このコードでは、order=3を指定することで、3次スプライン補間を行っています。スプライン補間は、多項式補間よりも滑らかな曲線を生成するため、特にデータに急激な変化がある場合や、曲線を滑らかに接続する必要がある場合に有効です。
スプライン補間は、非線形性が強いデータに対して有効で、線形補間や多項式補間では対応できない複雑なパターンをキャプチャできます。ただし、スプライン補間も補間対象のデータの特性に強く依存するため、適切な次数(order)を選ぶことが重要です。次数が高すぎると過剰にフィットしてしまう可能性があり、反対に低すぎるとトレンドを捉えきれない場合があります。
他の補間方法
interpolateメソッドは、線形補間や時間ベースの補間、スプライン補間だけでなく、他にもさまざまな補間方法をサポートしています。例えば、以下のような方法があります。
-
polynomial: 多項式補間。orderパラメータを指定して多項式の次数を設定します。
-
pad: 前方補完。直前の有効な値を使用して欠損値を埋めます。
-
nearest: 最近傍補完。欠損値に最も近い既存の値を使用します。
3次多項式による補間
|
1 2 |
df['value_poly_filled'] = df['value'].interpolate(method='polynomial', order=3) df |
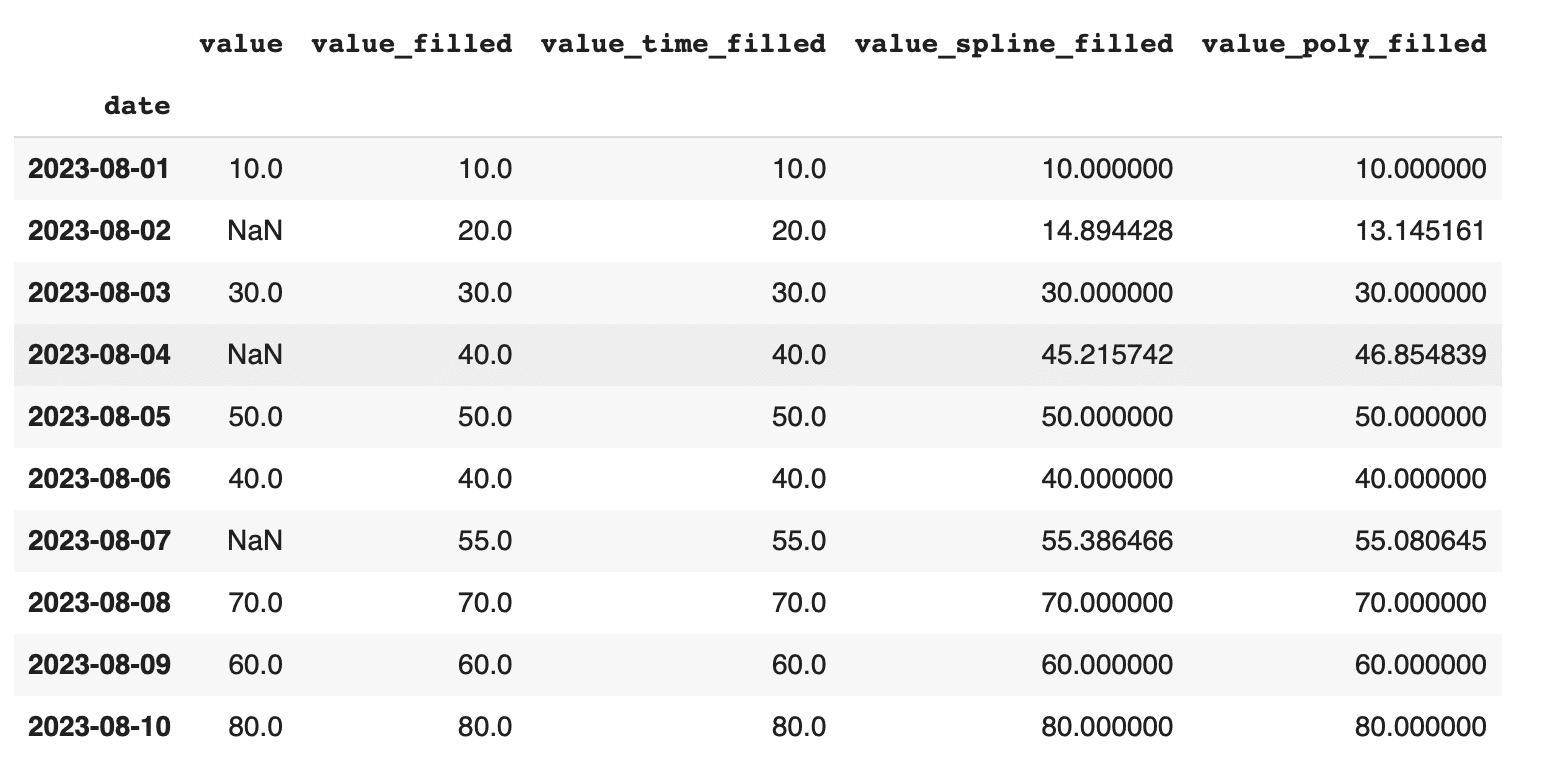
このコードでは、3次多項式を用いて欠損値を補完しています。多項式補間は、データに非線形なトレンドがある場合に有効です。
補間の精度と注意点
補間は欠損値を埋めるための強力なツールですが、いくつかの注意点もあります。補間はあくまで推定値であり、元のデータの正確な値ではありません。
特に、データの変動が大きい場合や、欠損値が連続している場合は、補間の結果が実際の値から大きく外れる可能性があります。
そのため、補間方法を選択する際には、データの性質や目的に応じて慎重に判断することが重要です。また、補間結果を検証するために、元のデータと補間後のデータを比較することをお勧めします。
まとめ
Pandasのinterpolateメソッドは、時系列データにおける欠損値を補完するための強力なツールです。
線形補間や時間ベースの補間、多項式補間、スプライン補間など、さまざまな補間方法を選択できるため、データの特性に合わせた適切な補間が可能です。
しかし、補間結果は推定値であることを忘れず、データの性質に応じた慎重な判断が必要な点には注意しましょう。
======================================================
さらにデータサイエンスを学んでいきたいという方向けに「Pythonによるデータサイエンス」動画を提供しています。
基礎編・応用編それぞれ35時間以上の動画となっており、今なら50%OFFですので、ぜひチェックしてみてください!
>>>Pythonによるデータサイエンス基礎編
>>>Pythonによるデータサイエンス応用編