
条件による行の抽出操作はデータフレームを扱う時によくやることですよね。
今回はPySparkでSpark DataFrameの行を条件によって抽出する方法を紹介します。
-

-
データサイエンティストとして3年間で3社経験した僕の転職体験談まとめ
こんにちわ、サトシです。33歳です。 今回は、データサイエンティストの3年間に3社で働いた僕が、データサイエンティストとしての転職活動についてまとめて書きたいと思います。 これまでSE→博士研究員→ポ ...
filterで条件による行の抽出
Pandasデータフレームで行を抽出したいときは例えば、df[df["A"]=="aa"]みたいな感じでできましたね。
一応説明しておくと、データフレームdfのA列の値が"aa"のレコード(行)を抽出するコードです。
PySparkでも同じやろと思ってやってみると、見事にエラーがでます。
PySparkではfilterメソッドを使う必要があるんです。
例えば、このようなデータフレームがあるとします。
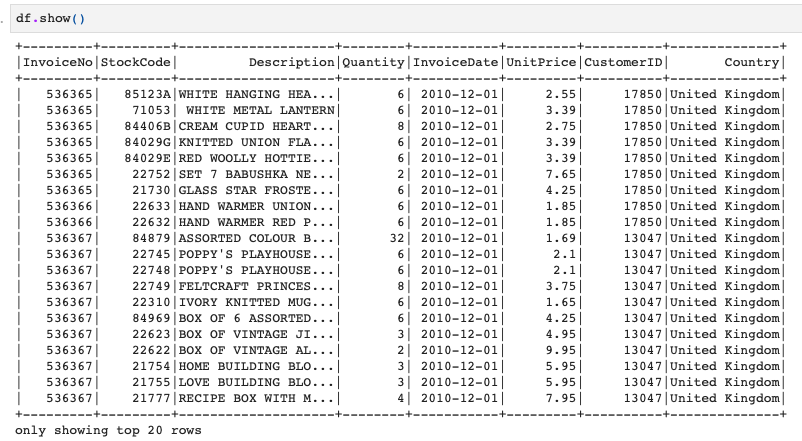
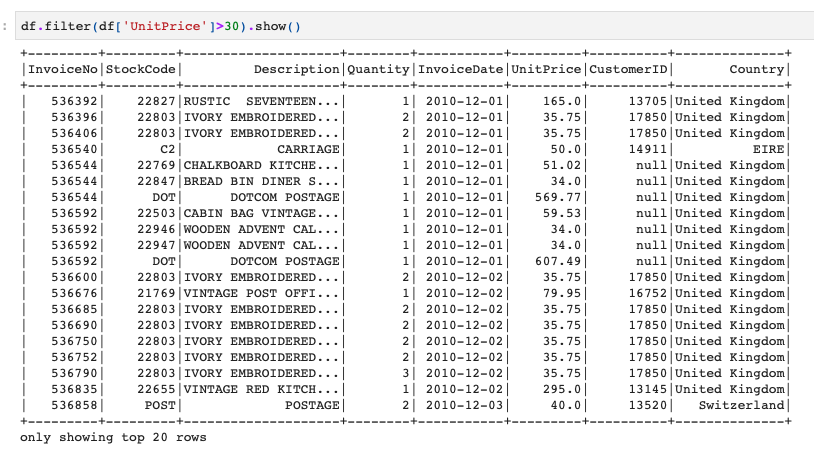
このときにUnitPrice列が30より大きい行を抽出してみましょう。
それはこのように、df.filterのカッコの中にデータフレームの条件を入力する形になります。
|
1 |
df.filter(df['UnitPrice']>30).show() |
ただ、行を表示するだけでなく、行数をカウントしたい場合は、抽出したあとに.count()をつければOKです。
|
1 |
df.filter(df['Description']=='unknown').count() |

ちょっと複雑な処理で集計した値に対して条件を設定する場合は、このように行うこともできます。
下の例は、Desctiption列の値でgroupbyをしてカウントし、そのカウント数が1000以上の場合にソートして表示するというものです。
|
1 2 |
# 購入された商品の中で1000回以上購入されている商品を大きい順に並べる df.groupby(df['Description']).count().filter("`count`>=1000").sort(asc("count")).show(truncate=False) |
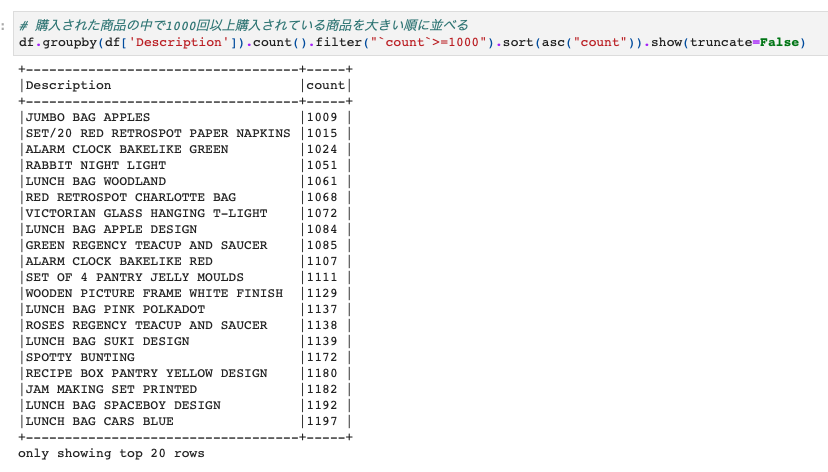
この場合は、filterのカッコの中はデータフレームdfの条件にはならず、前のカウント結果を使うので、filter("count>=1000")のようになっています。
データフレームの処理はよくやることだと思いますので、PySparkでもうまく扱えるとよいですね!
PySparkの勉強法
もしPySparkをちゃんと学びたい方はUdemyのコースがおすすめです。日本語の書籍は古いやつしかないからです。。。
【Udemy】PySparkによる大規模データ処理手法と機械学習
英語でもよい方は英語のこのあたりがわかりやすいです。

