
自然言語処理の技術は最近いろいろな場面で使われていますね。
僕は業務で自然言語を使うことが今までにほとんどなかったので、さすがにちょっと勉強してみないとなと思い、重い腰を上げてタイトルにもあるようにQiitaの転職記事を使った練習をしてみることにしました。
最近の自然言語処理というとBERTを使ったりとかGPT3だとかいろいろありますが、とりあえず基本に立ち返って以下のことをやってみたいと思います。
・ストップワード
・いらない文字の除去
・形態素解析
・単語カウント
・n-gram
・共起ネットワーク
など
とりあえずやりたいことは自然言語のデータに慣れることです。
機械学習とかはこれからということで、今回はデータハンドリングに重きを置きたいと思いますが、実際に頻出単語をカウントしたり、共起ネットワークを作るだけでも結構おもしろいものでした。
ぜひ、最後まで読んでいただけるとうれしいです!
※コードにはもっといい書き方があると思いますが、そこはご了承くださいませ。あと、一部コードも省略しています。
Qiita APIで記事の取得
まずは自然言語処理をやるにしても元データがなければ何もできないので、今回はエンジニア御用達のQiitaの記事を使わせていただくことにします。
QiitaはAPIが公開されていて、トークンを取得しさえすれば簡単に記事の取得を行うことができるのです。
ただし、なんのテーマもなく記事を取得してもよくわからないことになりそうなので、今回はタグに「転職」が含まれている記事を取得して分析することにします。
「転職」をテーマにした理由はただただエンジニア関連の方々がどんなふうに転職をしたか気になったからです(記事を読めよという話ですが。。。)。
トークンの取得
では、記事を取得するためにQiitaのトークンを取得します。
Qiita APIはトークンがなくても使うことができるのですが、トークンがあると取得できる記事数が多くなるので、取得しておいた方がいいです。無料ですので。
トークンは、まずQiitaにアカウントを作成したあとに、
設定→アプリケーション→新しくトークンを発行する
から取得することができます。
Qiita APIの説明はこちらですので、読んでおくとよいかと思います。
記事の取得
ではまず、記事を取得しましょう。
記事の取得はこのようにして行いました。
このソースはこちらのブログを大いに参考にさせていただきました。
https://harinez2.hateblo.jp/entry/qiita_api_by_python
今回は300記事を使用するということで、一度に100記事取得するループを3回回すというふうにしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import requests import json token = "トークンを入力" headers = { "Authorization": "Bearer " + token } letters = '' for i in range(3): params = { "page": str(i + 1), "per_page": "100", } #転職タグがついた記事を抽出 res = requests.get('https://qiita.com/api/v2/tags/転職/items', params=params, headers=headers) jsondata = json.loads(res.text) for item in jsondata: res = requests.get('https://qiita.com/api/v2/items/' + item['id'], headers=headers) json_content = json.loads(res.text) for body in json_content['rendered_body']: letters = letters + str(body) |

一応言っておくと、300記事という数に意味はありません。
実際にやってみて300記事くらいだったら僕のPCがまぁまぁ動くので、300記事にしたということです。
もっとたくさんでも快適に動くPCをお持ちの方はもっとたくさんの記事をダウンロードしてみてください。
ただし、qiita APIは1時間に1000記事までと決まっているみたいですので、その点は注意です。
あと、今回は転職記事を抽出するために、「転職」タグがついた記事を選んでいます。
自然言語データの処理
ここまでで転職タグのついた記事を抽出し、文字列に格納することができました。
次にやることは記事データの整形です。
BeautifulSoup4による整形
現段階では、抽出した文字列はこのようになっています。
htmlタグがいっぱいついていてこのままでは使い物になりません。
ということで、ここで便利なBeautifulSoupを使います。
BeautifulSoupはよくスクレイピングで使われるライブラリですが、これを使ってHTMLタグたちを一掃します。
|
1 2 3 4 5 |
import requests from bs4 import BeautifulSoup clear_text = BeautifulSoup(letters) clear_text_for_network = clear_text.get_text(',').split(',') |
これで元となるデータができました。
参考はこちらです。
https://note.com/marketscience/n/n924288db4a72
ストップワードの作成
次はストップワードを作ります。
こちらのSlothlibを使わせてもらいました。
ただしこれだと少し寂しいので、自力でいくつか加えました。
この加え方とかも正規表現とかいろいろ方法があるのかと思いますが、とりあえずベタ書き。
|
1 2 3 4 5 6 7 |
stop_word = pd.read_table("Japanese.txt", header=None) stop_list = stop_word[0].tolist() add_list = ["こと", "ん", "の", "さ","0","1","2","3","4","5","6","7","8","9","10","11","12" ,"月","2019年","2020年","2021年","2022年","2019","2020","2021","2022" ,"it","職","社","たん","こぴぺ","向け","非常","今後","僕","ありません" , "url", "Url", "URL","miriwo","率","items","よひ","1年","-1","-2","-3","図"] stop_list = stop_list + add_list |
転職記事の形態素解析
これで一応準備ができましたので、形態素解析を行います。
形態素解析にはMecabを使うことにしました。
Mecabのインストールは簡単にできましたが、ユーザ辞書をカスタムで使い方法にてこずり結局できませんでしたので、今回はカスタム辞書設定は割愛します。
command
brew install mecabbrew
install mecab-ipadic
というわけで辞書はipadicを使って行うことにします。
この辺りは、こちらの記事を参考にしました。
https://note.com/npaka/n/n949a421d428b#HqVwX
また、形態素解析したあとに使用する単語の品詞は、名詞のみに絞ることにしました。
なにせ分量が多いですし、名詞以外はけっこうゴミ単語が多いので、とりあえず重要そうな名詞を抽出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import MeCab as mc from collections import Counter dicdir = '-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd' def mecab_analysis(text): t = mc.Tagger(dicdir) t.parse('') node = t.parseToNode(text) output = [] while node: word_type = node.feature.split(",")[0] if word_type in ["名詞"] and node.surface not in stop_list: output.append(node.surface) node = node.next if node is None: break return output |
では、これを実行して結果をデータフレームに格納し、邪魔な文字とかも消去します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
new_list = [] for elem in clear_text_for_network: new = elem.replace("\n","") new = new.replace("「","") \ .replace("」","") \ .replace("、","") \ .replace("。","") \ .replace("(","") \ .replace(")","") \ .replace("(","") \ .replace(")","") \ .replace("・","") \ .replace("×","") \ .replace("!","") \ .replace("*","") \ .replace("○","") \ .replace("\u3000","") new_list.append(new) df2 = pd.DataFrame(new_list, columns=["articles"]) # 空白行を削除 import numpy as np df2['articles'].replace('', np.nan, inplace=True) df2.dropna(subset=['articles'], inplace=True) df2['words'] = df2['articles'].apply(mecab_analysis) |
これで単語ごとに分けることができました。
一部単語じゃねぇじゃねぇか、との声が聞こえそうですが、まぁこんなもんでしょう。
今のところ約12万単語といったところです。
単語カウント
unigram, bigram, trigram
ようやく形態素解析して単語に分割することができましたので、さっそく単語カウントをしてみたいと思います。
しかし、ただ単語の数を数えるだけでもいいのですが、単語と単語のつながりがわかったほうがよさそうということで、n-gramつまり、bi-gramとtri-gramも計算してみたいと思います。
これらの計算はnlplotを使うと便利です(https://www.takapy.work/entry/2020/05/17/192947)。
まずはunigramを作ります(同じ要領でbigram, trigramも作ります)。
|
1 2 3 4 5 6 7 8 9 10 11 |
import nlplot npt = nlplot.NLPlot(df2, target_col='words') stopwords = npt.get_stopword(top_n=0, min_freq=0) npt.bar_ngram( title='uni-gram', xaxis_label='word_count', yaxis_label='word', ngram=1, top_n=50, stopwords=stopwords ) |
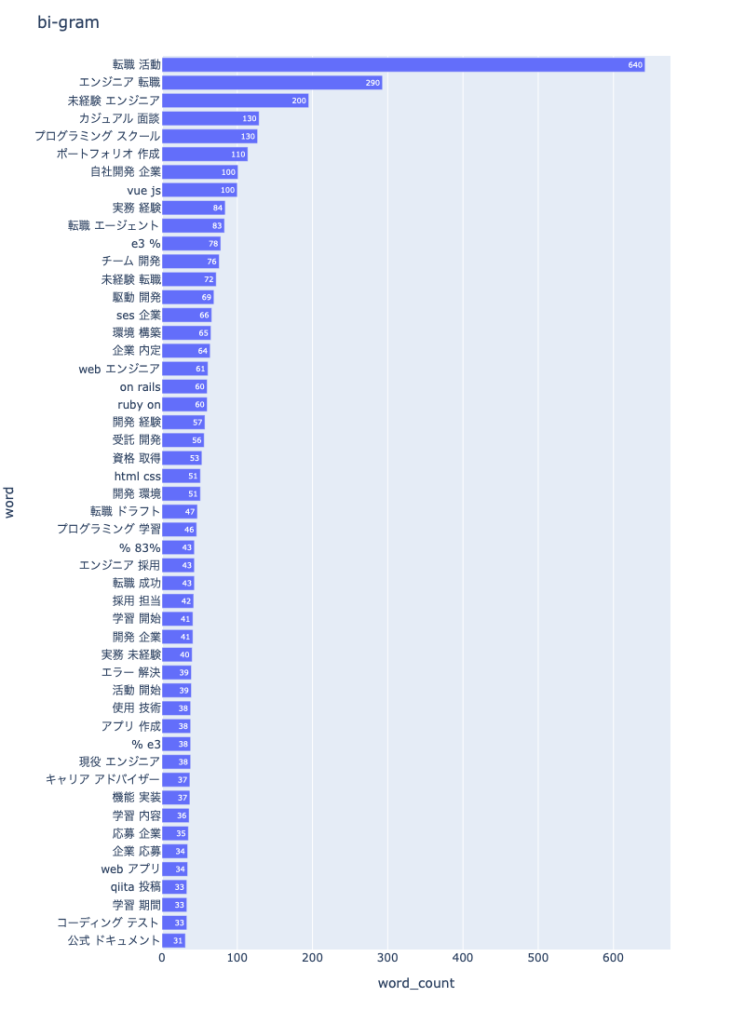
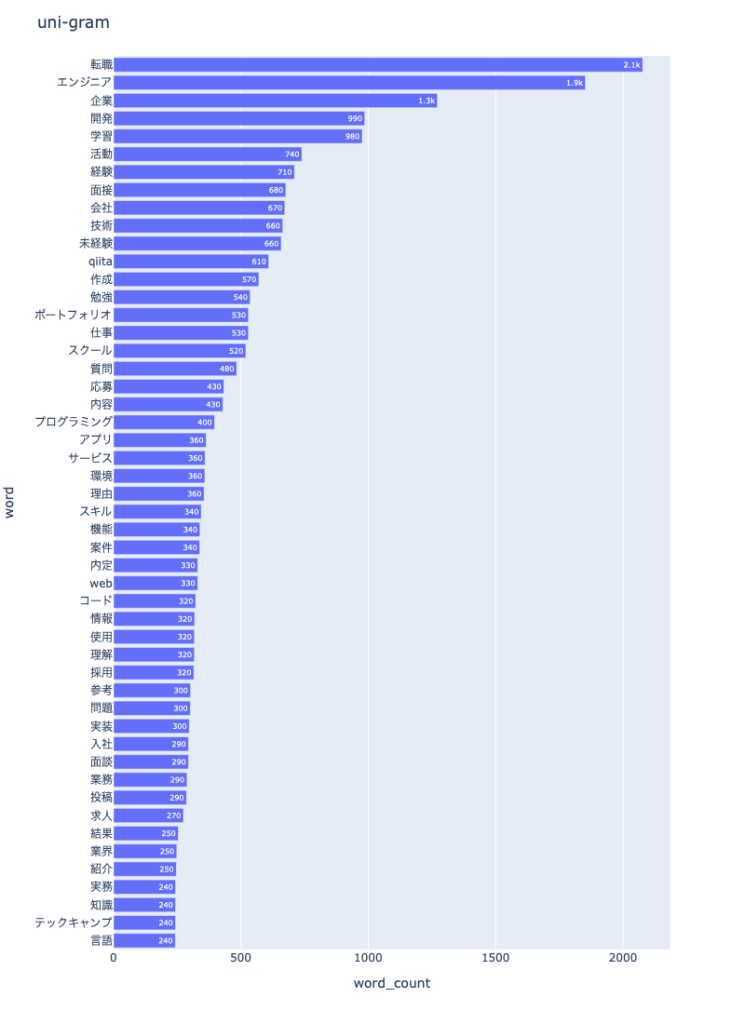 続いて、bi-gram。
続いて、bi-gram。
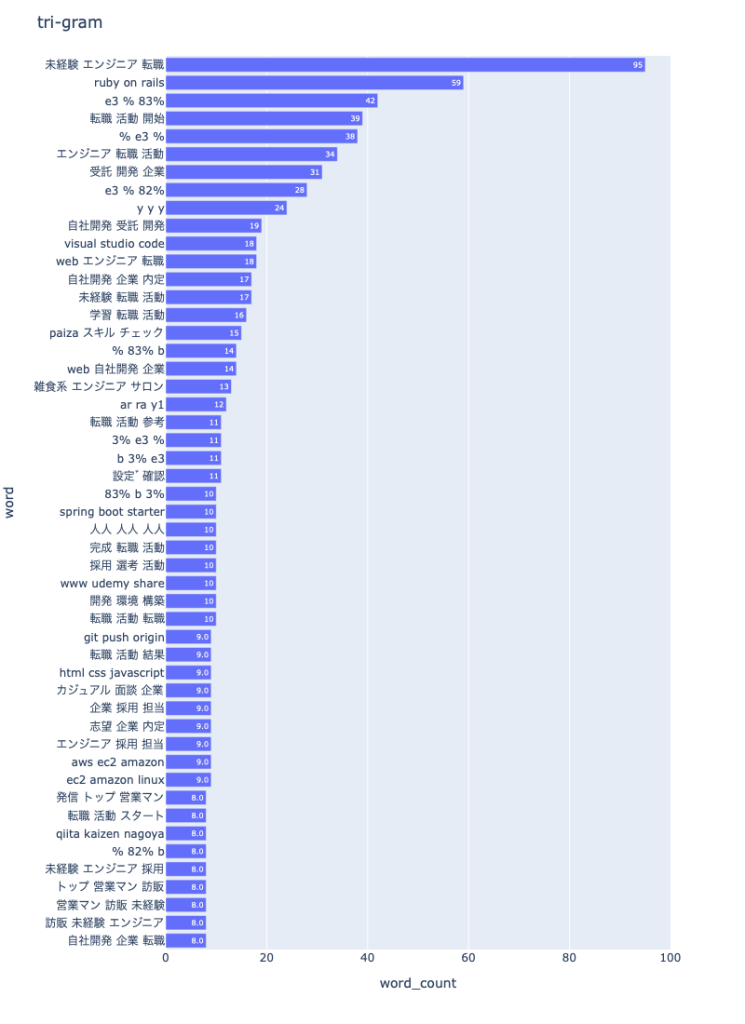
そして、tri-gramがこちら。
おまけにワードクラウドという、よく見るこんなのも作ることができます。
|
1 2 3 4 5 6 7 |
npt = nlplot.NLPlot(df2, target_col='words') npt.wordcloud( max_words=100, max_font_size=100, colormap='tab20_r', stopwords=stopwords ) |

見た目がなんかいい感じですよね笑
共起ネットワーク
共起ネットワークの作成
最後に共起ネットワークを作ってみたいと思います。
共起ネットワークは各文において、どんな単語と単語が同時に出現しているかをJaccard係数というものを用いて判定し、そのつながり具合をネットワークのように表すものです。
ものを見たほうが早いと思いますので、作っていきます。
とは言っても、ありがたいライブラリのおかげでコマンドちょっとでできます。
|
1 2 3 4 5 6 7 8 9 10 |
npt.build_graph(stopwords=stopwords, min_edge_frequency=20) display( npt.node_df.head(), npt.node_df.shape, npt.edge_df.head(), npt.edge_df.shape ) npt.co_network( title='Co-occurrence network', ) |
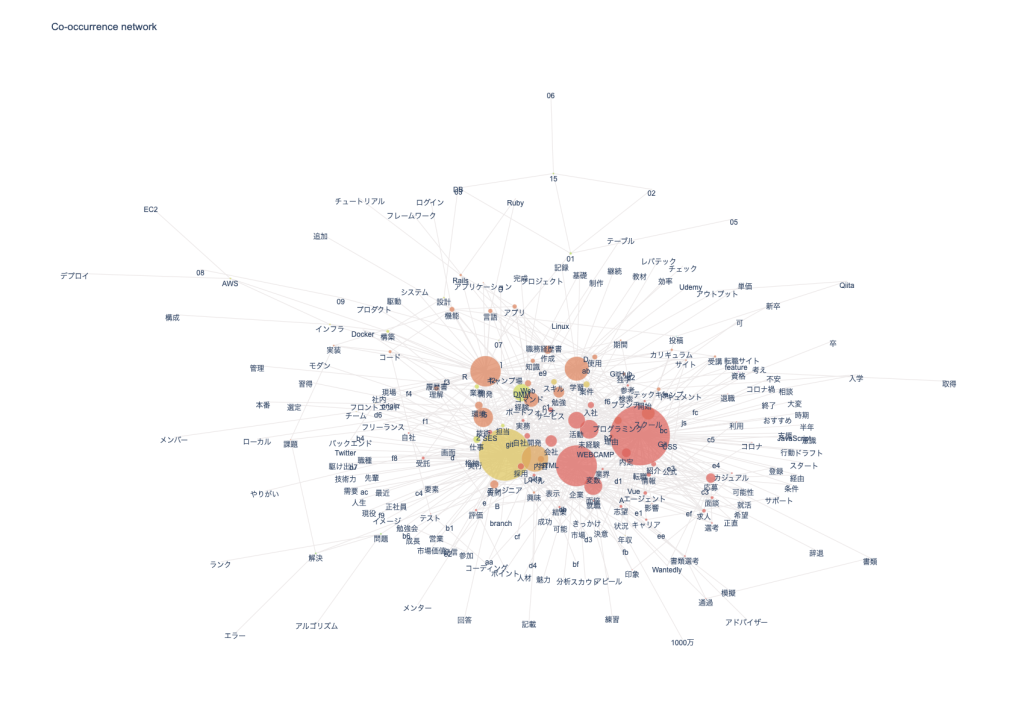
min_edge_frequencyの数を変えると少し見た目が変わります。
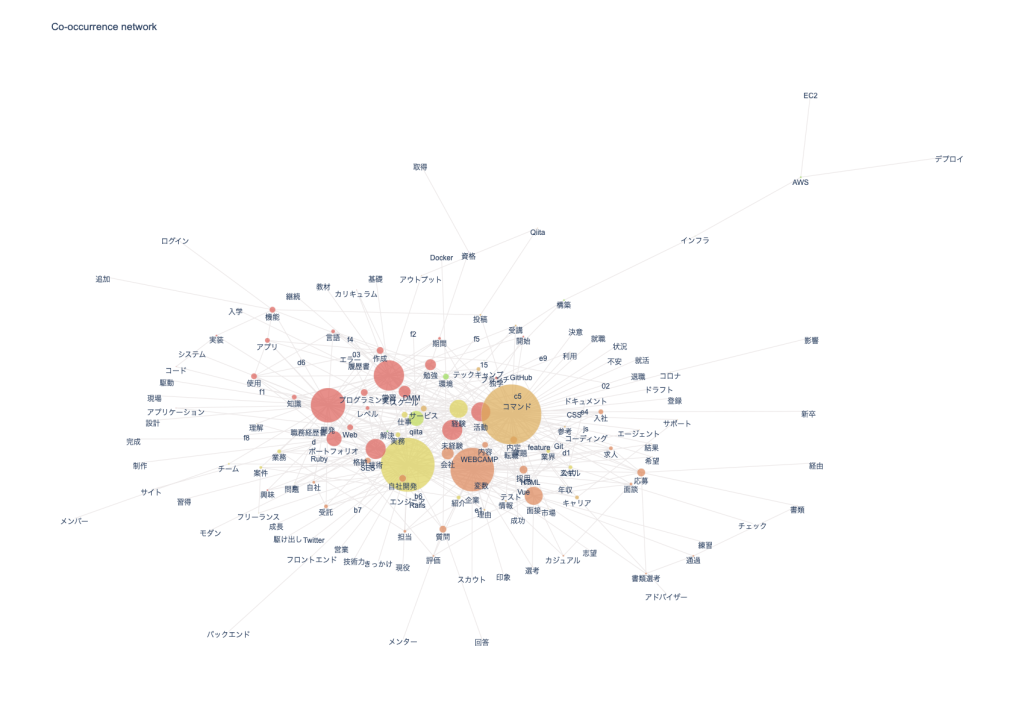
ちょっとごちゃごちゃしてしまってわかりづらい感もありますが、今回はこんなところで。
今回はPythonで作りましたが、KHcoderというソフトを使うとGUIでより簡単に、素敵な共起ネットワークの図が作れるので、こちらを使ってみるのもよいかと思います。
分析結果の確認
では、これで一通りのことが完了したので、結果をみていきたいと思います。
単語カウントについては、単語の数が多すぎるのでグラフには出していませんが、全単語のカウントもCSV出力しているので、それも参照しながらどんな単語が多いかみていきたいと思います。
ただし、一つの記事で同じワードを連発しているようなこともあるので、そこは注意が必要です。
あと共起ネットワークからは、文の中でどのような単語と単語が頻出しているかを想像しながらみていきましょう。
転職者はどんな人か
n-gramや単語カウントのCSVを見て、どのような人の記事なのか、転職者はどのような人なのかを想像していきます。
まず上位に「転職」とか「エンジニア」が来るのは当然です。
そしてだんだん下へと見ていくと、11番目に「未経験」というワードが出てきました。
意外と未経験からのエンジニア転職をする人たちが記事をたくさん書いてくれているということなのでしょうか?
bi-gramを見てみても、3番目に「未経験 エンジニア」というのがランクインしていますし、さらにtri-gramを見てみると、一位が「未経験 エンジニア 転職」ですから確定的でしょうかね。
あとは225位で「データサイエンティスト」というワードも81回出ているので、エンジニアだけでなくデータサイエンティストの人たちも記事を書いていることが想像できますね。
どのような手順や準備で転職活動しているか
では、どのような手順や準備をして転職活動しているか見てみます。
uni-gramの上記を見てみると、ここに「ポートフォリオ」「スクール」というワードがあるのがわかります。
やはりエンジニア転職なので自分のポートフォリオを用意して転職する人が多いのかもしれません。
「Github」も160回出ているので、やはりGithubにアップですかね。
また、「スクール」については未経験者のエンジニア転職が多いと予想されたことからもうかがえるように、未経験者がプログラミングスクールに通って学習しているみたいです。
uni-gramの48番目にも「テックキャンプ」とあるとおり、こういったスクールに通ってスキルを得てから転職しているのでしょうね。
次にどのようなスクールや媒体を使って転職しているかをもっとくわしく見てみます。
どのような媒体を使って転職活動してそうか
未経験者のエンジニア転職系の記事が多そうで、彼らがテックキャンプなどのスクールに通っていそうだということは想像できましたが、他にももっといろいろなサービスを活用していそうです。
プログラミングスクール系
テックキャンプ 240回
言わずと知れたプログラミングスクール 「テックキャンプ」です。
正直、こんなに上位に来るとは思わなかったので驚きです。
やはり未経験者のエンジニア就職には相当強いのでしょうか。
もしくは、テックキャンプはプログラミングスクールだけでなく、転職支援サービスもあるようなので、こちらを使っていた可能性もありますね!
Progate 69回
Progateは僕は知らなかったのですが、こちらもけっこう評判いいみたいですね。
ずいぶん安価にプログラミングを学ぶことができるみたいで、このあたりが人気の秘訣なのでしょうか。
DMMwebcamp 60回以上(複数の単語に分割されてしまっているため)
DMMwebcampもかなり多かったですね。
出現回数ではProgateに負けていますが、これはdmmとカウントされたりwebcampとカウントされたりと、書き方によって複数の単語に分割されてしまったからのようです。
なので少し実際より少なくはなっていますが、それでもこれだけ出現しています。
こちらも未経験からの学習にはかなり良さそうな感じですかね。
エージェント系
「エージェント」というワードが227回入ってましたので、やはり転職時には多くの人がエージェント経由で転職しているのでしょうか。
どんなエージェントを使っているかみていきます。
レバテック(キャリア) 83回
意外にかなり多かったのが、このレバテックです。
単語自体はレバテックだけではキャリアまで入っていなかったのですが、おそらくこちらの「レバテックキャリア」のことを指していると思います。
こちらはレバレジーズが運営している転職サービスで最近人気が高くなってます。
IT分野に特化したエージェントの方々に転職サポートをしてもらえるので、安心でよさそうですね!
転職ドラフト
「ドラフト」という単語が52回出ていました。
なにかと思いましたが、おそらく「転職ドラフト」のことかと思われます。
こちらはドラフトなので、未経験の方ではなく経験者向けの転職サービスになりそうですね。
経験豊富なQiitaユーザは自分から転職活動をするのではなく、このようにドラフトに申し込んで相手からオファーをもらう形式で転職しているのでしょうか。
転職サイト
ではエージェントサービスを持たない転職サイトを見ていきましょう。
Wantedly 118回
こちらかなり多く出現していました。
僕のイメージだとベンチャー系のエンジニアを多く募集しているのがWantedlyのイメージなので、未経験者の応募もありそうかなと思いました。
Green 49回
Greenは僕も以前使ったことがあるのですが、こちらも未経験向けの募集がけっこうあるので良さそうですね。
スキルアップ系
Udemy 71回
みんな知ってるUdemyです。
転職に直接役に立つ系ではありませんが、かなりの数出現していましたので、Udemyの講座でスキルアップを目指す人も多いでしょうね。
paiza 48回
![]()
paizaは練習問題をたくさん受けることができ、ランクを上げていくことで転職にも生かすことができるサービスでした。
単語カウントを見ているとSとかAとかがちょくちょく出ていたので、たぶんそれらのいくつかはpaizaのランクのことではないかと思います。
僕もAランクまでですが、やったことがあります。
paizaランクを上げてスキルをつけて転職するのもよさそうですね!
どんな技術を持ってそうな人か
プログラミング言語
さて、だんだん疲れてきたので、プログラミング言語については以下のようになっています。
| 言語 | 出現回数 |
| Vue | 182 |
| Rails | 171 |
| Ruby | 152 |
| PHP | 130 |
| Javascript | 127 |
| Laravel | 109 |
| CSS | 147 |
| React | 87 |
| Linux | 83 |
| Python | 72 |
僕はVueとかRailsとかは使ったことがないので感触はわかりませんが、最近のエンジニア界隈はこの辺りが有力なのでしょうか?
環境まわり
さて、最後に環境まわりを見ていきたいと思います。
まずはAWSが堂々の228回登場です。
そして、環境という区分に入れていいかわかりませんが、DockerやGitも多く登場していました。
| ワード | 出現回数 |
| AWS | 228 |
| Git | 141 |
| Docker | 120 |
この辺りはもう必須スキルなんですね。
僕として意外だったのは、AWSがとても多かったのに、GCPやAzureが少なかったことです。
エンジニア界隈ではやはりAWS一強なのでしょうか?
最後に
こんな感じで今回はQiitaの転職記事を題材に記事の取得から、簡単な処理、形態素解析、ワードカウント、共起ネットワークの作成を行いました。
共起ネットワークは図が小さくてみづらいのであまり触れませんでしたが、自分で作って拡大して見てみるとこれまた面白いです。
Qiitaの転職記事は未経験の転職が多そうだというのも新鮮でした。
ただし、一つの記事あたりの回数などを出しているわけではないので、ワードを連呼する記事があればそれに引っ張られてしまいますから、そのあたりは注意が必要です(今回はそれほど深入りしません)。
どんなサービスを使って転職してるか想像するのもおもしろかったので、今度はまた別の記事を題材に調べてみてもよさそうかと思いました。
最後まで読んでいただき、ありがとうございました!


