
今回はPySparkを使った線形回帰モデリングをやってみたいと思います。
PySparkではデータ処理にSpark DataFrameをよく使うかと思いますが、Sparkには機械学習を行うライブラリMLlibもあるので、機械学習も分散処理をすることができます。
ちなみにこちらの本をよく参考にさせていただきました。
Applied Data Science Using PySpark
使うデータはひとまずBankデータとして、その中の"balance"を目的変数として線形重回帰をやります。
PySparkのMLlibで線形重回帰のモデリング
CSVデータを読み込む
まずはSparkを使うためにSparkSessionを立ち上げます。
|
1 2 3 4 5 6 7 8 |
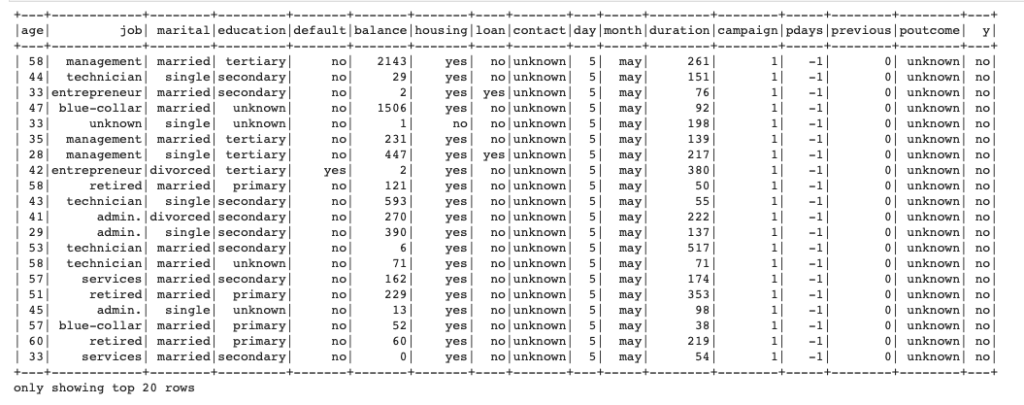
from pyspark.sql import SparkSession filename = 'bank/bank-full.csv' spark = SparkSession.builder \ .master("local") \ .appName("linear_regression") \ .getOrCreate() data = spark.read.csv(filename, header=True, inferSchema=True, sep=';') data.show() |
この辺りの細かいことの説明は省略しますので、興味があればSparkの公式をみてください。
spark sessionが立てられたら、CSVファイルを読み込みましょう。
CSV読み込みはread.csvで行うことができ、データにヘッダーがあるのでheaderはTrue、スキーマは勝手に推測してくれた方が楽なので、inferSchema=Trueにしておきます。最後にCSVデータはセミコロンで区切られているので、sep=";"とします。
これでdataにデータが格納されます。
訓練データとテストデータに分ける
|
1 2 |
train_df, test_df = data.select(['age','balance','campaign']) \ .randomSplit([0.7,0.3], seed=1) |
これでデータが読み込めたので、ランダムに7:3に訓練データとテストデータを分けましょう。
この訓練データを使ってモデリングをします。
本来は標準化とかもした方がよいのですが、一旦そういう細工はせずに進めます。

訓練用にAssembleする
さてここまでは今までにsklearnとかでやっていた感じとあまり変わりませんが、ここが少しsklearnでのモデリングと変わります。
MLlibでモデリングする場合は訓練データを各列に分割していてはダメで、訓練データの列データを一つのリストにまとめる必要があります。
それにはVectorAssemblerを使うとその操作を行ってくれます。
今回はパイプラインに登録するので、assembleまでしかしませんが、パイプラインに登録しないのであればfitも行う必要があります。
|
1 2 3 4 5 |
#データ作成ステージ from pyspark.ml.feature import VectorAssembler target = 'balance' features = ['age','campaign'] assemble = VectorAssembler(inputCols=features, outputCol='features') |
線形重回帰のモデリング
これでAssembleを行ってモデリングをするデータの準備ができたので、実際にモデリングをしてみます。
モデリング自体は簡単で、説明変数のカラムと目的変数の方を指定して、LinearRegressionすればOKです。
|
1 2 3 |
#線形重回帰モデリングステージ from pyspark.ml.regression import LinearRegression clf = LinearRegression(featuresCol='features', labelCol='balance') |
パイプラインに登録
さて、ここまでassembleとclfを定義しましたので、それをパイプラインに登録したいと思います。
今回は2つしか登録しませんが、標準化したり、one-hotエンコーディングしたり、精度評価したりなども合わせた場合は、パイプラインを使うとずっと楽になりますので、使うと良いです。
|
1 2 3 4 |
#パイプラインにステージの登録 from pyspark.ml.pipeline import Pipeline pipeline = Pipeline(stages=[assemble, clf]) model = pipeline.fit(train_df) |
最後にこのpipelineをfitしてモデリングができます。
推論の実行
モデリングができたので訓練データで推論を行いましょう。
|
1 2 |
#推論 pred_train = model.transform(train_df) |
RMSEによる精度評価
最後に精度評価を行います。
今回は線形重回帰による数値予測ですから、RMSEを計算することで評価してみます。
pipelineをfitした結果がmodel変数に入っているのですが、こちらにはassembleの情報も入っています。
なので、この場合はmodel.stages[1]とするとパイプラインのステージに登録した1番目(0始まり)の要素ということで、model.stages[1]のように指定します。
|
1 2 3 |
#RMSE eval = model.stages[1].summary print("RMSE={}".format(eval.rootMeanSquaredError)) |
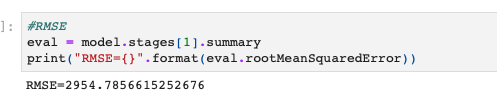
これでRMSEの確認ができましたね!
回帰係数の確認
RMSEが計算できたので、線形回帰係数も出しておきましょう。
回帰係数もRMSEと同様にmodel.stages[1]のあとにcoefficient, interceptとすれば、係数や切片の値を確認できます。
|
1 2 3 |
#係数表示 print("coefficient={}".format(model.stages[1].coefficients)) print("intercept={}".format(model.stages[1].intercept)) |

これで訓練データを使って行うことが完了です!
テストデータでの実行
モデリングができたので、あとはテストデータでも実行してみましょう。
もうパイプラインが登録されているので、テストデータをmodelに投入すれば推論ができます。
簡単ですね!
|
1 2 |
#テストデータでの実行 pred_test = model.transform(test_df) |
とりあえず今回はここまでにしておきたいと思います。
最低限のことを書きましたが、もっと多くの処理を行う場合はこのような流れの中に追加していくイメージかと思います。