
Pythonで簡単なデモアプリを作りたいことはあるかと思います。
データサイエンティストなどがモデリングをした際に、そのモデリング結果を使ってアプリの本番まではいかなくともデモのアプリが作れるとだいぶ幅が広がるでしょう。
もちろんしっかりとアプリを作るならばDjangoとかFlaskとかを使うかと思いますが、もっとライトにもっと簡単に作れたらなぁと思うので僕だけではないのではないでしょうか。
そこで今回はStreamlitというライブラリを使って、簡単な機械学習アプリを作ってみたいと思います。
Pythonで簡単にアプリが作れるライブラリはStreamlitとかDashとかいろいろありますが、とりあえずその中でも一番簡単なレベルだと思うStreamlitを使ってみます。
機械学習WEBアプリの作成
今回作ってみるのは、Irisのデータを使って花弁の長さ等をインプットしたら、予測されるIrisの種類を返してもらうという簡単なアプリです。
ではこちら初めていきましょう!
データの読み込み
Irisのデータはsklearnのdatasetからインポートします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 基本ライブラリー import numpy as np import pandas as pd # データセット ## データの読み込み from sklearn.datasets import load_iris iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['target'] = iris.target df.loc[df['target'] == 0, 'target'] = "setosa" df.loc[df['target'] == 1, 'target'] = "versicolor" df.loc[df['target'] == 2, 'target'] = "virginica" |
モデリング
データの準備ができたので、機械学習アプリのためのモデリングをしていきます。
本当はアプリとは別でモデリングをして、その結果のみを読み込むようにすれば良いと思いますが、今回はわかりやすさのために、アプリと同じコードの中でモデリングもしたいと思います。
なので、モデリング自体には全然精度は求めず、とりあえずロジスティック回帰でモデリングだけします。
|
1 2 3 4 5 6 7 |
# 予測モデル構築 X = iris.data[:, [0, 2]] y = iris.target from sklearn.linear_model import LogisticRegression clf = LogisticRegression() clf.fit(X, y) |
アプリ部分のコーディング
これでモデリングができましたので、重要なアプリ部分のコーディングをしていきましょう。
Streamlitを使ったアプリでは、大きくサイドパネル部分とメインパネルの部分があります。
今回はサイドパネルでがく弁の長さ(sepal length)、花弁の長さ(petal length)を決められるようにし、その結果を読み込んで、画面上にIrisの種類の予測結果を返します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# アプリ import streamlit as st ## サイドパネル(インプット部) st.sidebar.header('Input Features') sepalValue = st.sidebar.slider('sepal length (cm)', min_value=0.0, max_value=10.0, step=0.1) petalValue = st.sidebar.slider('petal length (cm)', min_value=0.0, max_value=10.0, step=0.1) ## メインパネル st.title("Iris Classifier") st.write("## Input value") ### インプットデータ(1行のデータフレーム) value_df = pd.DataFrame([],columns=['data','sepal length (cm)','petal length (cm)']) record = pd.Series(['data',sepalValue, petalValue], index=value_df.columns) value_df = value_df.append(record, ignore_index=True) value_df.set_index("data",inplace=True) |
予測と結果出力
インプットデータができましたので、このデータを使って予測をします。
そして予測結果を出力してみましょう!
|
1 2 3 4 5 6 7 8 9 10 11 |
### 予測 pred_probs = clf.predict_proba(value_df) pred_df = pd.DataFrame(pred_probs,columns=['setosa','versicolor','virginica'],index=['probability']) ### 結果出力 st.write(value_df) st.write("## Output probability") st.write(pred_df) name = pred_df.idxmax(axis=1).tolist() st.write("## Result") st.write('このアイリスはきっと',str(name[0]),"です!") |
サイドパネルで決めた値をメインパネルのInput Valueに反映させるようにし、その予測結果を確率で出すようにします。
そして一番確率が高いIrisの種類を結果のところに表示させます。
"st.write"でアプリ画面に文字表示ができるのですが、マークダウン形式で表示できますので、好きな感じにインデントとか文字サイズとか決めます。
これで無事コードができたので、ターミナルでpython app.py とすると、ちゃんとコードが正しいことがわかります。
command
python app.py
下の方に、"Streamlit run app.py"をしろと出るのでそれに従って実行すると、このようにブラウザにアプリが表示されます。
command
streamlit run app.py
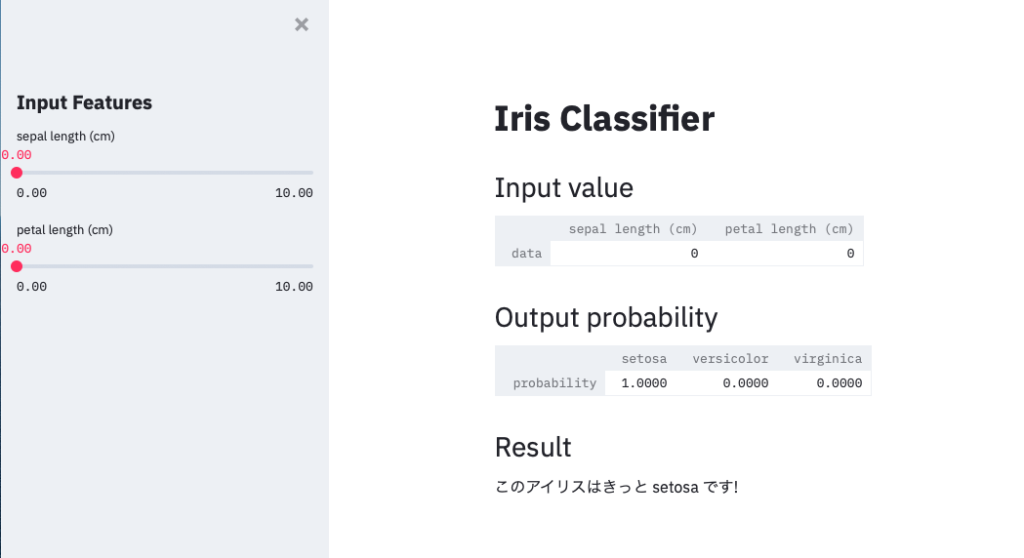
サイドパネルのスライダーを動かすと、結果にあるIris種類の予測結果が変わることがわかりますね!
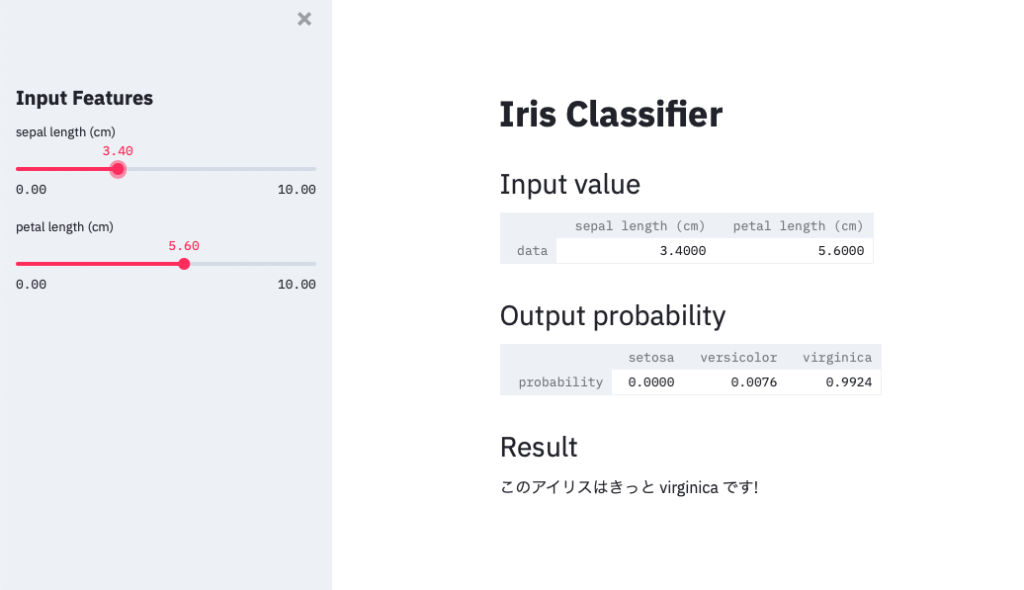
このように今回は単純な例でしたが、Streamlitを使えば簡単にWEBアプリを作れることがわかりました。
もう少しがんばれば、いろいろとカスタマイズができそうです!