transform()メソッドは、グループごとの計算を行いつつ、その結果を元のデータフレームに統合してくれます。
といってもわかりづらいので、transform()メソッドの挙動を見ていきましょう。
このメソッドは、あるグループごとの統計量を計算し、その結果を元のデータセットに適用するために使用されます。
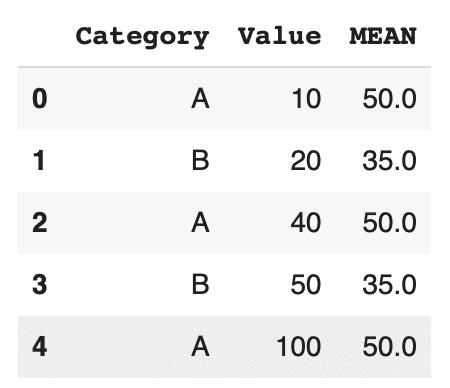
例えば、以下のコードでは、カテゴリごとに列の平均値を計算し、新しい列'Mean'に結果を格納しています。
注目すべきはレコードが減っていないところです。カテゴリごとに平均してその結果を結合した形になっています。
|
1 2 3 4 |
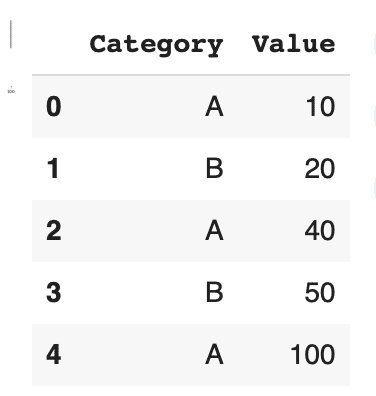
import pandas as pd data = {'Category': ['A', 'B', 'A', 'B', 'A'], 'Value': [10, 20, 30, 40, 50]} df = pd.DataFrame(data) df |
|
1 2 |
df['MEAN'] = df.groupby('Category')['Value'].transform('mean') df |
|
1 2 3 4 |
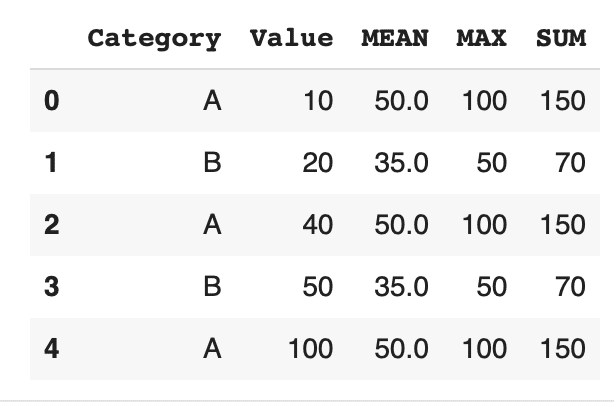
df['MAX'] = df.groupby('Category')['Value'].transform('max') df['MIN'] = df.groupby('Category')['Value'].transform('min') df['SUM'] = df.groupby('Category')['Value'].transform('sum') df |
======================================================
さらにデータサイエンスを学んでいきたいという方向けに「Pythonによるデータサイエンス」動画を提供しています。
基礎編・応用編それぞれ35時間以上の動画となっており、今なら50%OFFですので、ぜひチェックしてみてください!
>>>Pythonによるデータサイエンス基礎編
>>>Pythonによるデータサイエンス応用編