
Pandasのデータフレームを操作するときに、各列に対して異なる集計関数を適用したいこともありますよね。
でも普通にデータフレームに対してmeanとかMaxなどを適用しても全数値列に対して適用されるだけで、異なる集計関数を同時に適用できません。
というわけで各列に異なる集計関数を適用する方法を備忘として残しておきたいと思います。
-

-
データサイエンティストとして3年間で3社経験した僕の転職体験談まとめ
こんにちわ、サトシです。33歳です。 今回は、データサイエンティストの3年間に3社で働いた僕が、データサイエンティストとしての転職活動についてまとめて書きたいと思います。 これまでSE→博士研究員→ポ ...
aggとgroupbyによる異なる集計関数の適用
まずは適当なPandasデータフレームを作ります。
|
1 2 3 4 |
data = [["A", 10., 3],["B", 25., 2],["C", 32., 4],["A",41., 1],["C",50., 5]] col_name = ["id","col1","col2"] df = pd.DataFrame(data=data, columns=col_name) df |
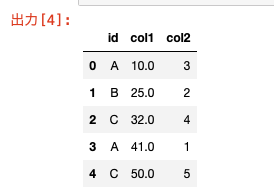
今、ID列とcol1, col2列のあるデータフレームを作りました。
このcol1, col2列に対していろいろな集計関数を適用して、その結果をデータフレームに入れたいと思います。
ただ、まずは普通にというか直接データフレームに集計関数を適用するとこのような具合になります。
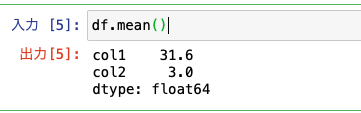
ここではmean関数がcol1, col2にそれぞれ適用されて、2つの列の平均が算出されています。
今回やりたいのはこういうことではありませんね。
次にid列でgroupbyしてcol1, col2の平均を出してみます。

このようになりました。
だいぶやりたいことに近づいてきました。
しかしまだid列ごとに集計ができたとはいえ、同じ集計関数しか適用できていません。
やりたいのは、id列でgroupbyして、同時にcol1列のカウント・合計、col2列の最大・平均の算出などです。
こちらはaggメソッドを使うことで実現できます(aggはaggregationの略ですね)。
|
1 2 3 4 |
df.groupby("id").agg(sum_value1=("col1","sum") , count_value2=("col2","count") , mean_value2=("col2","mean") , max_value1=("col1","max") ) |
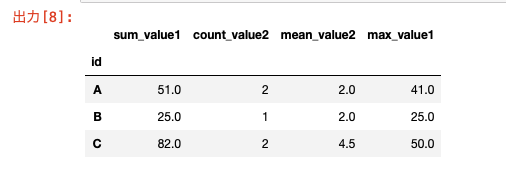
結果もこのようになり、やりたいことができていると思います。
ちゃんと集計をしたあとの列名も指定の名前にできるので良いですね!
こんな感じでgroupbyとaggを使って、各列に対してidごとに複数の集計関数を適用することができます。
-

-
データサイエンティスト経験3年の僕がフリーランスとして独立するまでの体験談
こんにちわ、サトシです。 今回は、企業でデータサイエンティストとして働いていた僕が、フリーランスとしてどのような手順で独立していったかについて書いていきたいと思います。 僕はSIer SE→博士過程→ ...