大規模データを処理するときにはSparkを使うことが多くなってきたのではないでしょうか。
Apache Sparkはいろいろなプログラミング言語をサポートしており、JavaやScala、RにPythonでも使うことができます。
データ分析をする上では今はPythonが一般的ですから、僕もPythonでSparkを使う、つまりPySparkを使おうとしたことがあります。
そのときどのように環境設定をしたかというとDocker HubのDocker imageを使うとすごく簡単に環境構築ができましたので、そのことを書いておきたいと思います。
もしこれからPySparkの環境構築をしたい、PySparkをJupyterLabやJupyter notebookで使いたいけれどどのように環境を作ったら良いかわからない、という方には参考になるかと思いますのでぜひ最後まで読んでいただけるとうれしいです!
Docker HubのPySpark Docker imageを使う
Docker Hub
Docker HubというのはいろいろなDocker imageを集めたDocker用のGithub的なものだと思っていただければOKです。
こちらのURLにアクセスするとこのようなサイトにログインできます。
https://hub.docker.com
右の方を見るとSign inとかありますが、こちらは全部無視してよく、上の検索窓に検索したDocker imageのキーワードを入れます。

今回はPysparkと入れてみると、Pyspark用のDocker imageが検索されますのでこれらは誰でも使うことができます。
おすすめは一番上の"jupyter/pyspark-notebook"です。シンプルに一番スターが多くダウンロード数も多いのでこれで良いかと思います。
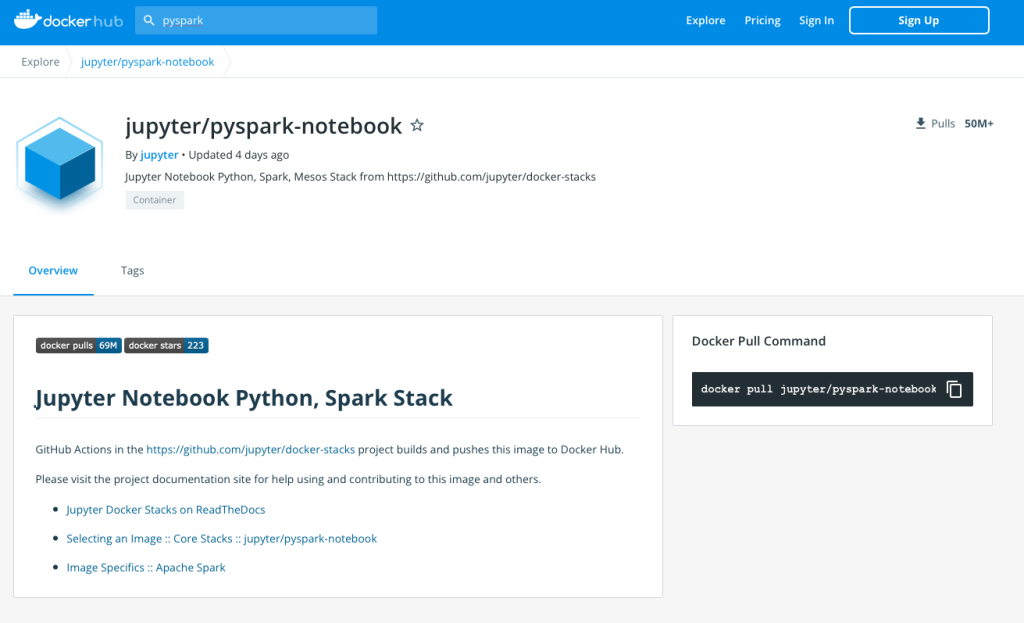
使ってみても問題なしです。
"jupyter/pyspark-notebook" imageのpull
では、このjupyter/pyspark-notebookを使う方法は大きく二つあり、一つ目はDocker imageのPullです。
command
docker pull jupyter/pyspark-notebook
こちらのコマンドでDocker pullができます。
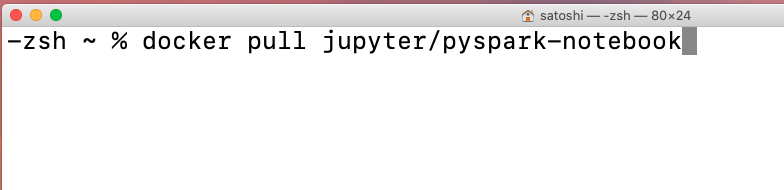
するとこのようにpullができ、結果的にこのようにdocker imageが作られました。

Dockerfileを使ってビルドしたい場合
もしpullをしない場合はDockerfileというファイルを作って、そちらに下の一行だけ書いてビルドすればよいです。
from jupyter/pyspark-notebook
ビルドはこのようなコマンドでできます。
command
docker build -t pyspark-image .
Docker runして使う
さて、これでDocker imageができたらあとはdocker runして使うだけです。
例えばこんな感じでdocker runします。
command
docker run -it --rm -p 8888:8888 -v ${PWD}:/home/jovyan/work "image IDを入力"

このimageではdocker runすると自動でJupyteLabが使えるようになるので、画面に出るURLをコピーしてブラウザに貼り付けると、JupyterLabが起動して使えるようになります。