
データフレームの結合処理はPandasでもよくやりますよね。
PySparkでも結合処理は同じようにやることができますので、基本的な結合処理を確認しておきたいと思います。
ただし、僕の独断と偏見で、inner joinとleft joinだけ書いておきます(僕のイメージでは9割くらいの結合処理はinner joinとleft joinで事足りると思っているためです)。
ちなみにオフィシャルはこちらですので、詳しいことはこちらを参照ください。
https://spark.apache.org/docs/3.1.1/api/python/reference/api/pyspark.sql.DataFrame.join.html
-

-
データサイエンティストとして3年間で3社経験した僕の転職体験談まとめ
こんにちわ、サトシです。33歳です。 今回は、データサイエンティストの3年間に3社で働いた僕が、データサイエンティストとしての転職活動についてまとめて書きたいと思います。 これまでSE→博士研究員→ポ ...
PySparkでデータフレームの結合処理
Inner join
さて、まずはInner join(内部結合)ですね。
とりあえずデータの準備として、これら2つの適当なSpark DataFrameを用意することにします。
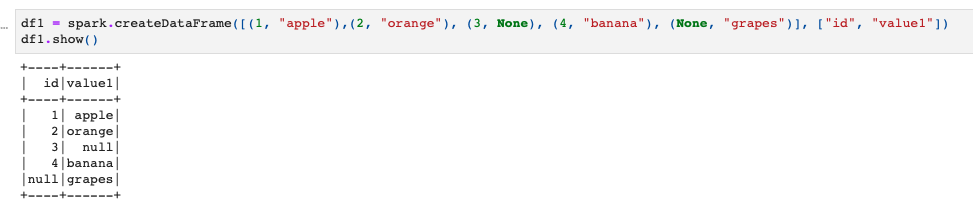
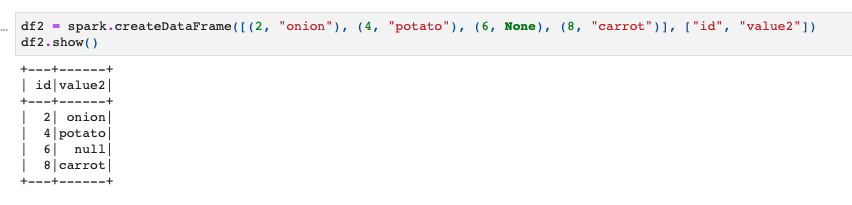
ではこの2つのデータフレームを使ってInner joinをしてみましょう。
やり方は次の通りで、結果はこのようになります。
|
1 2 |
# inner join df1.join(df2, "id", "inner").show() |
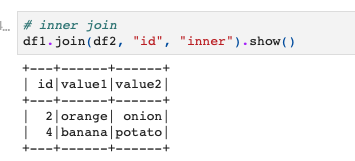
joinのカッコの中に、(結合したいデータフレーム, 結合キー, 結合方法)とします。
今回はinner joinなので、結合方法は"inner"となり、結合キーは"id"です。
idが共通の2, 4のレコードだけ抽出されていますね。
Left join
では、left joinもやってみましょう。
left joinの場合は結合方法を"leftouter"とします(leftでもいいっぽい)。
想像できるかと思いますが、もしright joinしたい場合は"rightouter"とすればOKです(rightでもいいっぽい)。
|
1 2 |
# left df1.join(df2, "id", "leftouter").show() |

こんな感じで無事left joinできています。
df1にleft joinするのでdf1は全て保持されたまま、そこにdf2の情報が付け加えられているというふうになっていますね!
とまぁ私の偏見でinner joinとleft joinだけやりましたが、もちろんcross joinとかもできますので、状況に応じて使い分けましょう。
PySparkの勉強法
もしPySparkをちゃんと学びたい方はUdemyのコースがおすすめです。日本語の書籍は古いやつしかないからです。。。
【Udemy】PySparkによる大規模データ処理手法と機械学習
英語でもよい方は英語のこのあたりがわかりやすいです。