
前回の記事ではPySparkでCSVファイルを読み込む方法をやりましたので、今回はCSVファイル出力をやりたいと思います。
ただし、ただCSVファイルに出力するだけでなく、PySparkらしく分散保存を体感しながら複数ファイルに分けたり、パーティションに分けて(データを複数のフォルダに分けて)保存する方法を紹介します。
というより、何も指定せずに保存すると複数のファイルに別れて保存されますので、その辺りをちゃんと指定できるようにしていきましょう!
-

-
データサイエンティストとして3年間で3社経験した僕の転職体験談まとめ
こんにちわ、サトシです。33歳です。 今回は、データサイエンティストの3年間に3社で働いた僕が、データサイエンティストとしての転職活動についてまとめて書きたいと思います。 これまでSE→博士研究員→ポ ...
とりあえずCSVファイル出力
まずはPySparkでの基本的なCSVファイル出力をやっていきます。
データはこのonline_retailデータを使います。
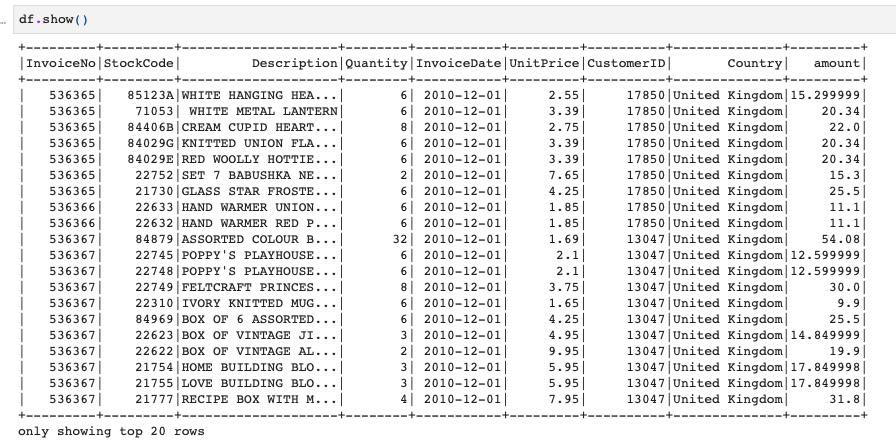
今、このdfという変数がSpark DataFrameになっていますので、こちらをCSVファイルで出力します。
Sparkでは一つのデータフレームでも分散保存していますので、このデータフレームを以下のように普通に保存するとどうなるでしょうか。
|
1 |
df.write.format("csv").option("delimiter", ",").save("save_dataframe") |
save()の中はCSVファイルを格納するフォルダ名です。
では、その保存先のフォルダ(今回は"save_dataframe")を見てみるとこのようになっています。
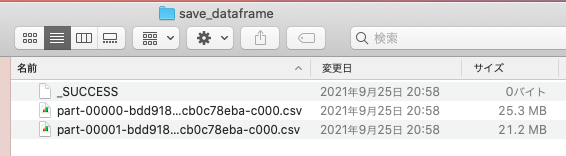
フォルダ内には3つのファイルがあり、_SUCCESSという空ファイルと、データが入っているCSVファイルが2つ入っていますね。
ポイントはCSVファイルが2つあることです。
特別なオプションなど付けずに保存しても、分散保存されていることがわかるかと思います。
一つのCSVファイルに出力
普通に保存すると複数のファイルに別れて保存されますので、1つのCSVにしたいときはどうすればいいかをやってみます。
方法としては、writeの前にcoalesce(1)と指定することです。そのほかは同じです。
|
1 2 |
#分散保存されたデータフレームをひとつにまとめて保存 df.coalesce(1).write.format("csv").option("delimiter", ",").save("./data/save_coalesce_dataframe") |
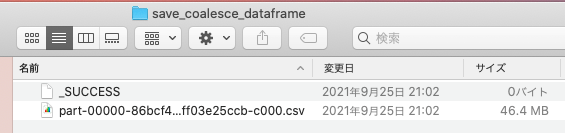
こちらで保存すると、このように_SUCESSという空ファイルと1つのCSVファイルになっています。
パーティション(複数フォルダ)に分けてCSVファイル出力
では最後にパーティション分けして(複数フォルダに分けて)保存をしてみましょう。
そのための準備として、日付カラムを使って、"year", "month"カラムを新しく作り、この2つのカラムでパーティション分けして保存してみたいと思います。
|
1 2 3 |
df_tmp = df.withColumn("purchase_year", year("InvoiceDate")) \ .withColumn("purchase_month", month("InvoiceDate")) df_tmp.show() |
はい、これでデータができました。
パーティションに分ける場合は、writeの後にpartitionByでパーティションに分けるカラムを指定します。
これで保存をするとどうなるでしょうか?
|
1 2 |
df_tmp.write.partitionBy("purchase_year", "purchase_month").format("csv") \ .option("delimiter", ",").save("./data/save_partition_dataframe") |
まずフォルダ構成はこのようになります。
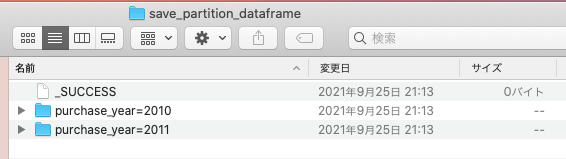
今回のデータには、yearは2010か2011しかありませんので、まずフォルダが2010, 2011の2つになっています。
次に2011年のフォルダに移動すると、このように月ごとにさらにフォルダがあるかと思います。
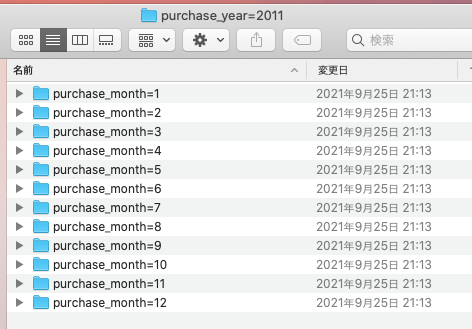
1月のフォルダに移動すると、ようやくCSVファイルが現れます。
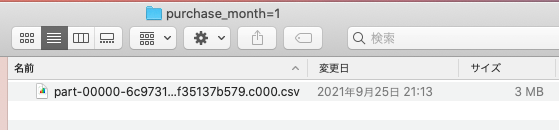
このように1つのSpark DataFrameが、パーティションに指定したカラムの値に応じてパーティション分け(フォルダ分け)されて保存されます。
それほど大きくないデータでしたらメリットはないかもですが、だんだんとデータが大きくなっていくとこのような分散保存の効果が聞いてくるかと思います。
PySparkの勉強法
もしPySparkをちゃんと学びたい方はUdemyのコースがおすすめです。日本語の書籍は古いやつしかないからです。。。
【Udemy】PySparkによる大規模データ処理手法と機械学習
英語でもよい方は英語のこのあたりがわかりやすいです。